Как в Excel построить поле корреляции
Корреляцию в Excel можно найти по формуле:
Результат показан ниже
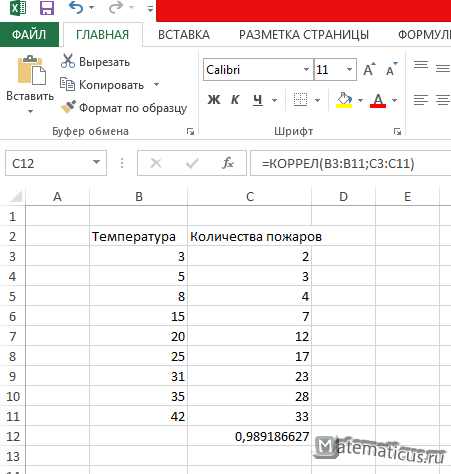
Также можно построить график поля корреляции
Для этого, переходим на вкладку Вставка в области диаграммы выбираем точечный график
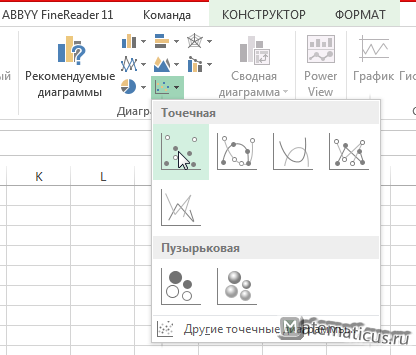
затем переходим на область графика
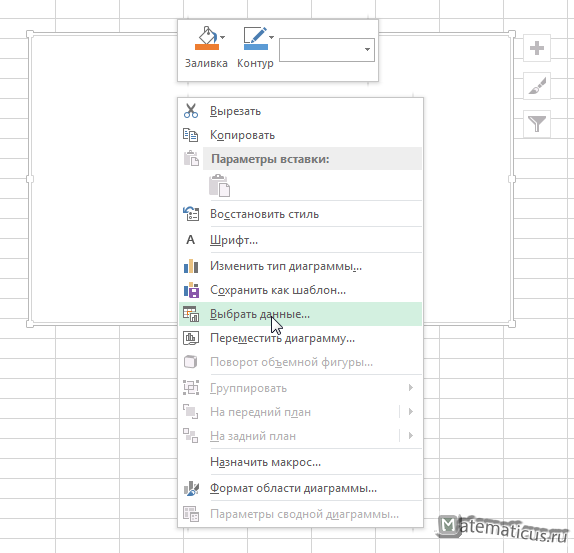
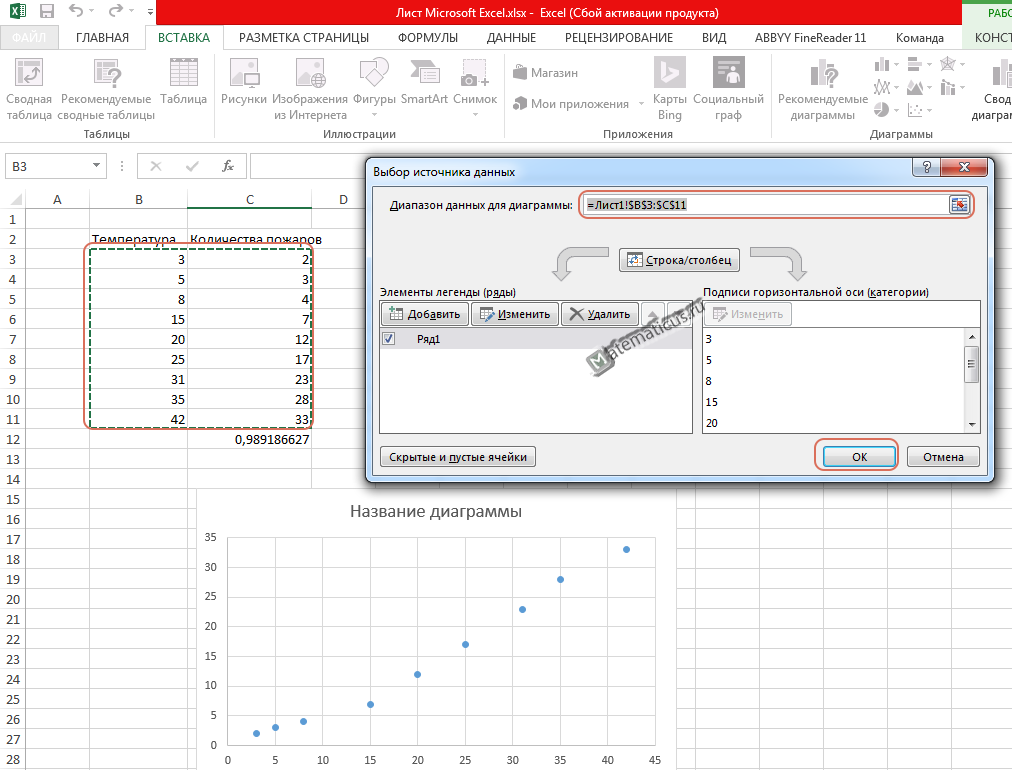
и выбираем данные из диапазона B3:C11, затем Ок. В итоги получаем график поля корреляции по точкам
Также быстро корреляцию можно найти через анализ данных
Вкладка Данные, затем Анализ данных. Если у вас эта вкладка не отображается в Excel, то см. здесь как сделать надстройку.
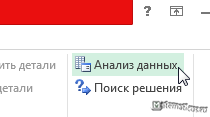
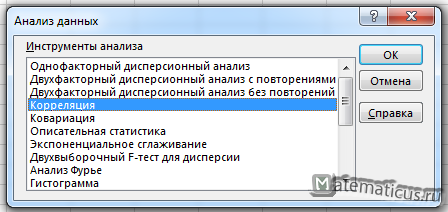
Выбираем корреляцию и жмём Ок.
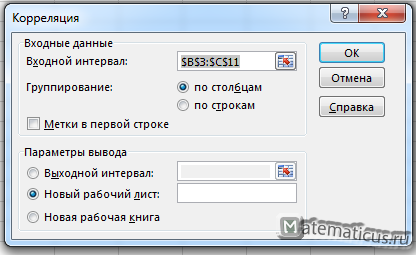
Такой же выбираем диапазон данных, как и ранее делали
В результате получаем отчёт

Аналитически, корреляция определяется по формуле:
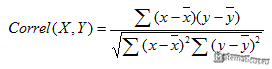
Насколько публикация полезна?
Нажмите на звезду, чтобы оценить!
Средняя оценка 4.6 / 5. Количество оценок: 5
Как построить график корреляции в Excel
Excel – это эффективный инструмент для статистической обработки данных. И определение корреляций является очень важной составляющей этого процесса. Программа имеет весь необходимый инструментарий для осуществления расчетов такого плана. Сегодня мы более детально разберемся, что нам нужно для осуществления анализа этого типа.
Что представляет собой корреляционный анализ
Простыми словами, корреляция – это связь между двумя явлениями. В свою очередь, под корреляционным анализом подразумевают выявление этой связи. Очень частое утверждение гласит, что корреляция – это зависимость между разными объектами, но на деле это неточное определение. Ведь существует множество изображений, которые показывают связь между явлениями, которые никак не могут быть зависимы друг от друга или одного третьего фактора, который влияет на них.
Для определения зависимости используется другой тип анализа, который называется регрессионным.
Интересный факт: корреляции делятся на истинные и ложные. То есть, иногда то, что графики идут в одинаковом направлении, может быть чистой случайностью, а не закономерным следствием воздействия одной переменной на другую или влияния общего фактора на обе переменные. В узких кругах довольно популярны картинки, где коррелируют между собой абсолютно не связанные явления. Вот некоторые примеры:
Ну и наконец, еще один пример ложной корреляции – чем больше сыра люди едят, тем больше людей умирает из-за того, что они запутываются в своих простынях.
Поэтому несмотря на то, что корреляция является эффективным статистическим инструментом, нужно учиться отфильтровывать истинные взаимосвязи между явлениями и ложные. Иначе исследование может получить такие интересные результаты. А теперь переходим непосредственно к тому, как проводить корреляционный анализ в Excel.
Корреляционный анализ в Excel – 2 способа
Вычисление коэффициента корреляции осуществляется двумя способами. Первый – это использование Мастера функций, который позволяет ввести формулу КОРРЕЛ. Второй инструмент – это пакет анализа, требующий отдельной активации.
Как рассчитать коэффициент корреляции
Давайте продемонстрируем механизм получения коэффициента корреляции на реальном кейсе. Допустим, у нас есть таблица с информацией о суммах продаж и рекламу. Нам нужно понять, в какой степени количество продаж и количество денег, которые были использованы на продвижение, взаимосвязаны.
Способ 1. Определение корреляции с помощью Мастера Функций
Функция КОРРЕЛ – один из самых простых методов, как можно реализовать поставленную задачу. В своем общем виде этот оператор имеет следующий вид: КОРРЕЛ(массив1;массив2). Как же ее ввести? Для этого нужно осуществлять следующие действия:
После выполнения описанных выше шагов мы видим в ячейке, выбранной нами на первом этапе, коэффициент корреляции. В нашем примере он составляет 0,97, что указывает на очень сильно выраженную взаимосвязь между данными двух диапазонов. 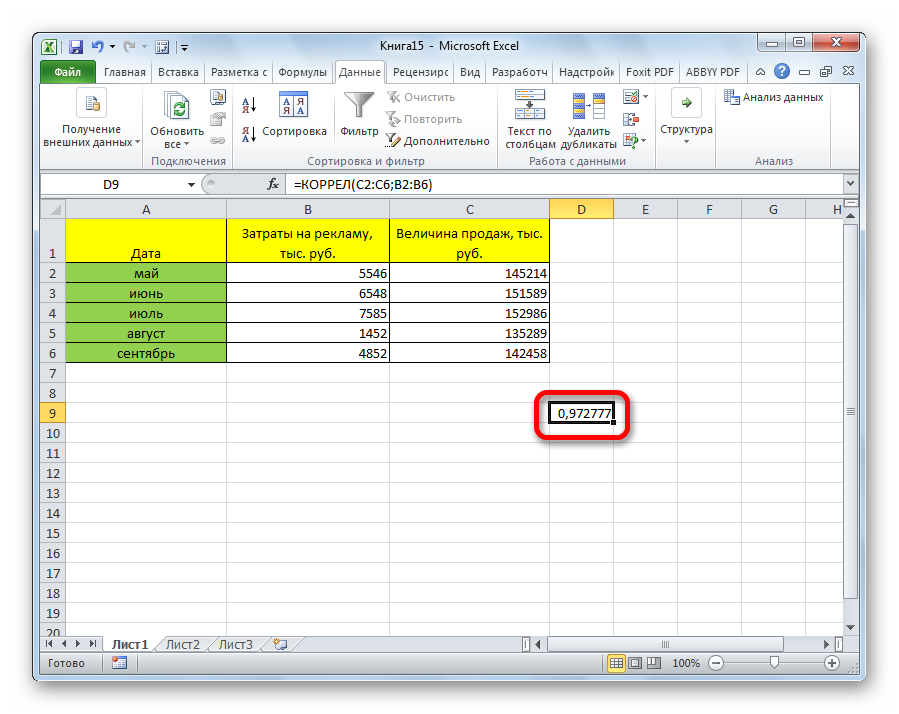
Способ 2. Вычисление корреляции с помощью пакета анализа
Также довольно неплохой инструмент для определения корреляции между двумя диапазонами – пакет анализа. Но перед тем, как его использовать, нам надо его включить. Для этого выполняем следующие действия:
Все, теперь наша надстройка включена. Теперь мы во вкладке «Данные» можем увидеть кнопку «Анализ данных». Если она появилась, то мы все сделали правильно. Нажимаем на нее. 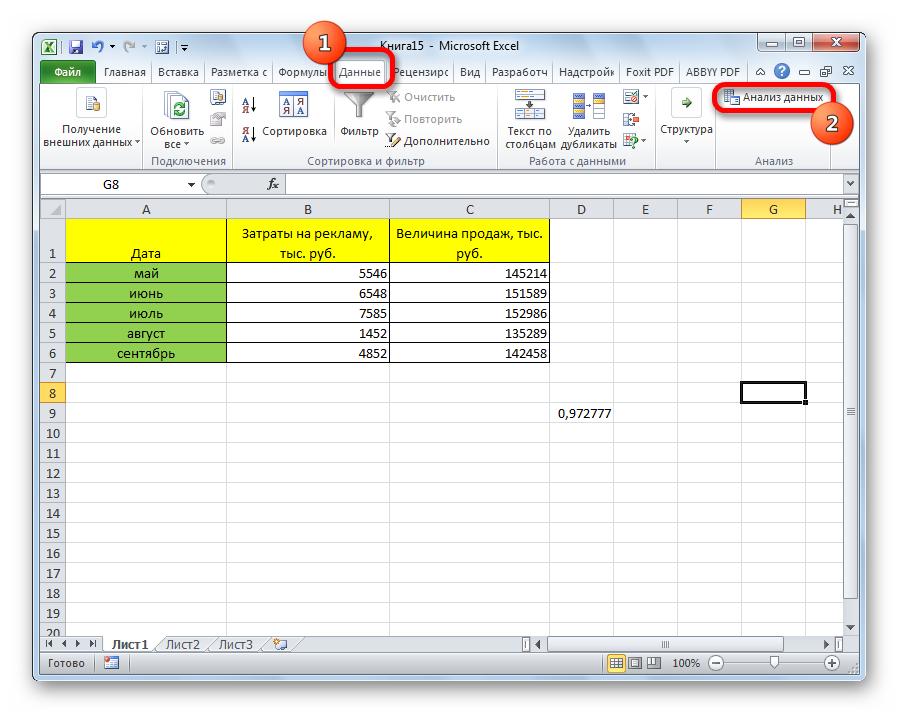
Появляется перечень с выбором разных способов анализа информации. Нам следует выбрать пункт «Корреляция» и нажать на «ОК». 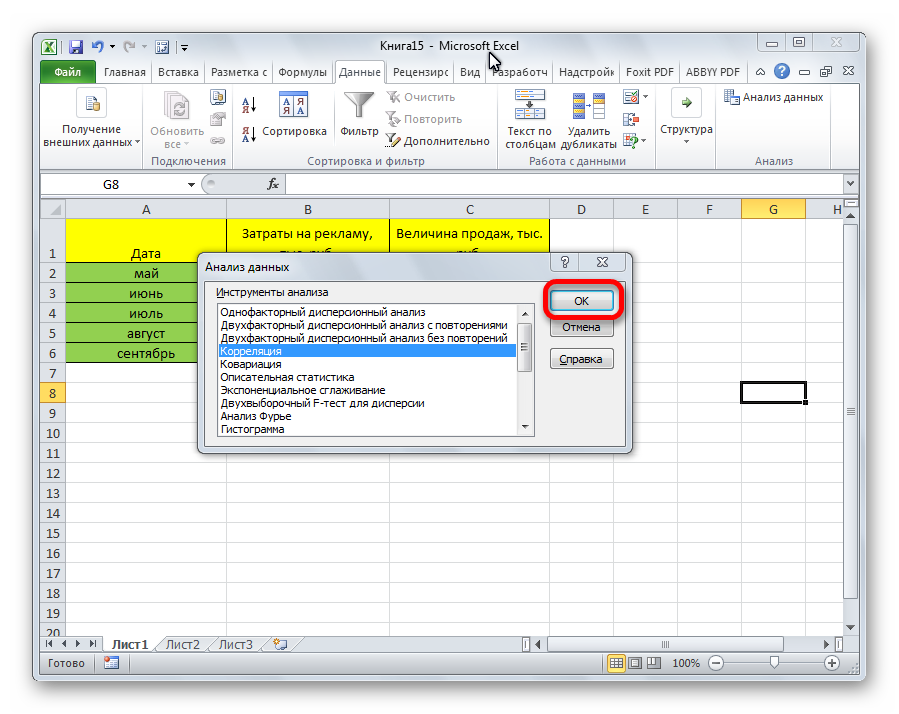
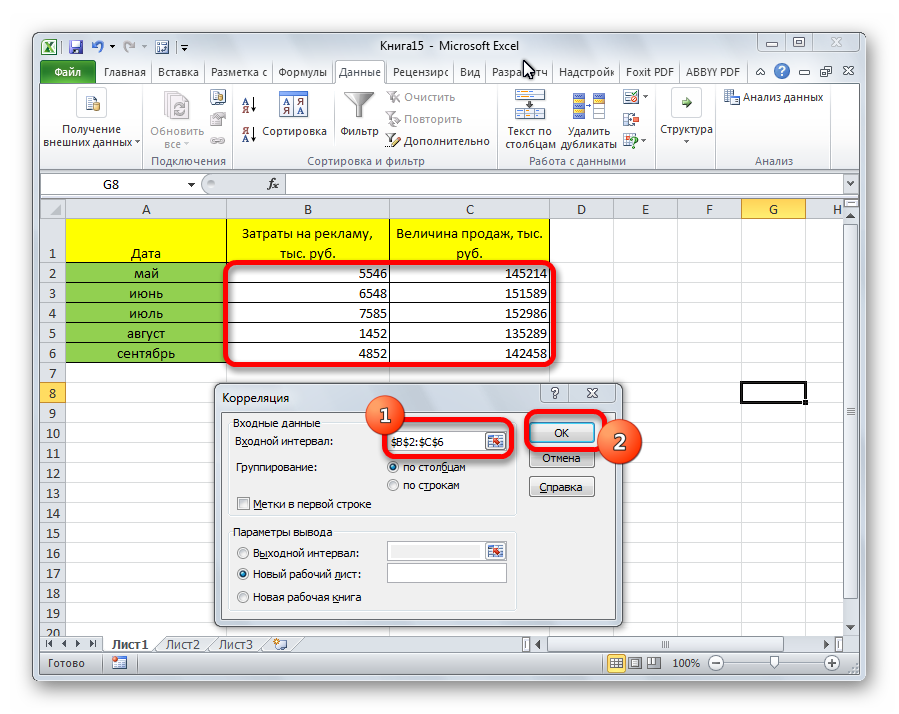
Затем нам нужно ввести настройки. Основное отличие этого метода от предыдущего заключается в том, что нам нужно вводить полностью диапазон, а не разрывать его на две части. В нашем случае, это информация, указанная в двух столбцах «Затраты на рекламу» и «Величина продаж».
Не вносим никаких изменений в параметр «Группирование». По умолчанию выставлен пункт «По столбцам», и он правильный. Эта настройка определяет, каким образом программа будет разбивать данные. Если же наши данные были бы представлены в двух рядах, то надо было бы изменить этот пункт на «По строкам».
В настройках вывода уже стоит пункт «Новый рабочий лист». То есть, информация о корреляции будет располагаться на отдельном листе. Пользователь может настроить место самостоятельно с помощью соответствующего переключателя – на текущий лист или в отдельный файл. Проверяем, все ли настройки были введены правильно. Если да, подтверждаем свои действия нажатием на клавишу «ОК».
Поскольку мы оставили поле с данными о том, куда будут выводиться результаты, таким, каким оно было, мы переходим на новый лист. На нем можно найти коэффициент корреляции. Конечно, он такой же самый, как был в предыдущем методе – 0,97. Причина этого в том, что вычисления производятся одинаковые, исходные данные мы также не меняли. Просто разными методами, но не более. 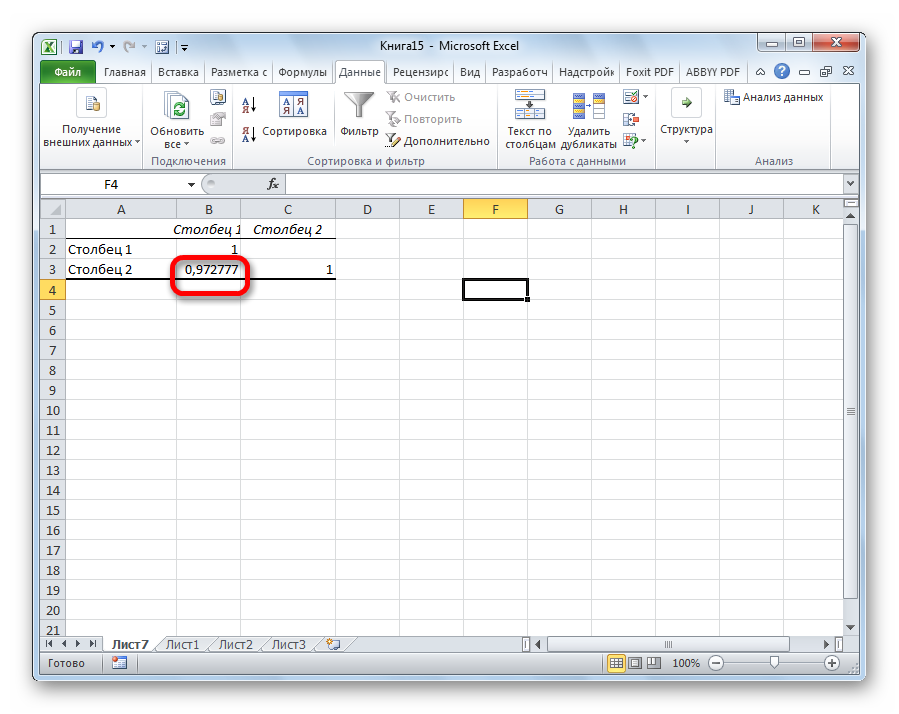
Таким образом, Эксель дает сразу два метода осуществления корреляционного анализа. Как вы уже понимаете, в результате вычислений итог получится таким же. Но каждый пользователь может выбрать тот метод расчета, который ему больше всего подходит.
Как построить поле корреляции в Excel
Итак, давайте теперь разберемся, как построить поле корреляции. Для начала нужно разобраться, что это вообще такое. Под корреляционным полем подразумевается фактически график корреляции. Главное требование к такой диаграмме – каждая точка должна соответствовать единице совокупности. Поле корреляции поможет установить более глубокие связи и проанализировать данные более качественно. Для начала нам нужно найти коэффициент корреляции между двумя диапазонами, используя функцию КОРРЕЛ. 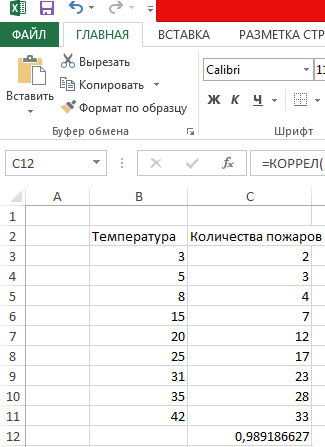
После того, как мы это сделали, мы теперь можем сделать поле корреляции. Для этого выполняем следующие действия:
Этот график можно построить не только на основе корреляции, определенной через функцию КОРРЕЛ.
Диаграмма рассеивания. Поле корреляции
До сих пор часть пользователей сидит на старой версии Word. Как построить корреляционное поле в этом случае? Для этого существует специальный инструмент, который называется мастером диаграмм. Найти его можно на панели инструментов по специфическому изображению диаграммы. Если навести на эту иконку мышкой, то появится всплывающая подсказка, которая поможет нам убедиться в том, что это действительно мастер диаграмм.
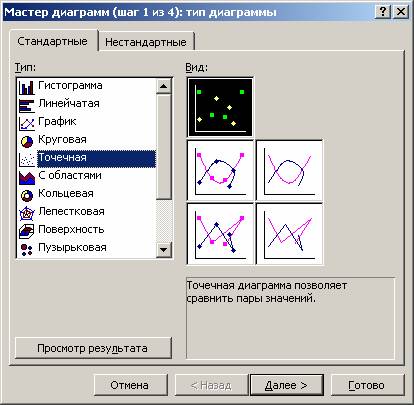
После этого появится диалоговое окно, в котором нам надо выбрать точечный тип диаграммы. Видим, что логика действий в старых версиях офисного пакета в целом остается той же самой, просто немного другой интерфейс. Немного правее мы можем увидеть, как будет выглядеть точечная диаграмма и выбрать подходящий вид, а также прочитать описание этого типа диаграммы. После этого нажимаем на кнопку «Далее».
Затем выбираем диапазон данных, и наша линия появляется. После этого можно добавить линию регрессии к графику. Для этого необходимо сделать клик правой кнопкой мыши по одной из точек и в появившемся перечне найти «Добавить линию тренда» и сделать клик по этому пункту. 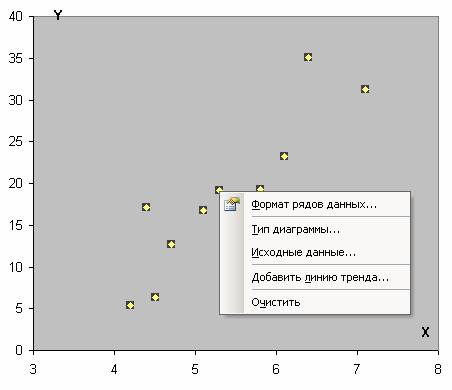
Далее выставляем настройки. Нас интересует тип «Линейная», а в окне параметров нужно поставить флажок «Показывать уравнение на диаграмме». 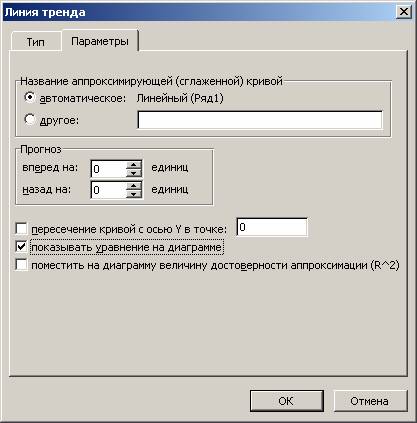
После подтверждения действий у нас появится что-то типа такого графика.
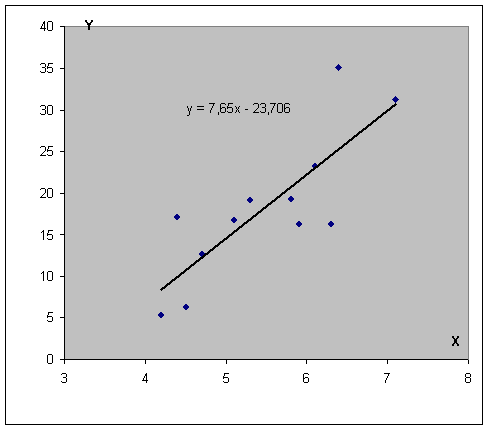
Как видим, возможных вариантов построения может быть огромное количество.
Строим поле корреляции.




![]()
![]()
Содержание отчета
2. Краткие теоретические сведения.
3. Порядок выполнения работы.
4. Исходные данные для разработки математической модели.
5. Результаты разработки математической модели.
6. Результаты исследования модели. Построение прогноза.
В задачах 2-4 можно использовать ППП Excel для расчетов характеристик модели.
Работа № 1.
Построение моделей парной регрессии. Проверка остатков на гетероскедастичность.
По 15 предприятиям, выпускающим один и тот же вид продукции известны значения двух признаков:
| x | y |
| 5,3 | 18,4 |
| 15,1 | 22,0 |
| 24,2 | 32,3 |
| 7,1 | 16,4 |
| 11,0 | 22,2 |
| 8,5 | 21,7 |
| 14,5 | 23,6 |
| 10,2 | 18,5 |
| 18,6 | 26,1 |
| 19,7 | 30,2 |
| 21,3 | 28,6 |
| 22,1 | 34,0 |
| 4,1 | 14,2 |
| 12,0 | 22,1 |
| 18,3 | 28,2 |
Требуется:
1. Построить поле корреляции и сформулировать гипотезу о форме связи.
2. Построить модели:
Линейной парной регрессии.
Полулогарифмической парной регрессии.
2.3 Степенной парной регрессии.
Для этого:
Рассчитать параметры уравнений.
2. Оценить тесноту связи с помощью коэффициента (индекса)
корреляции.
3. Оценить качество модели с помощью коэффициента (индекса)
детерминации и средней ошибки аппроксимации.
4. Дать с помощью среднего коэффициента эластичности
сравнительную оценку силы связи фактора с результатом.
5. С помощью F-критерия Фишера оценить статистическую надежность результатов регрессионного моделирования.
По значениям характеристик, рассчитанных в пунктах 2-5 выбрать лучшее уравнение регрессии.
Используя метод Гольфрельда-Квандта проверить остатки на гетероскедастичность.
8. Рассчитать прогнозное значение результата, если прогнозное значение фактора увеличится на 5% от его среднего уровня. Для уровня значимости  =0,05 определить доверительный интервал прогноза.
=0,05 определить доверительный интервал прогноза.
Строим поле корреляции.

2.1. Модель линейной парной регрессии.
2.1.1. Рассчитаем параметры a и b линейной регрессии у=а+bх.
Строим расчетную таблицу 1.
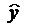
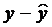
Параметры a и b уравнения
определяются методом наименьших квадратов:
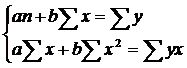
Разделив на n и решая методом Крамера, получаем формулу для определения b:
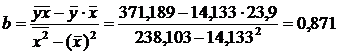
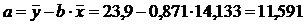
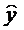 =11,591+0,871x
=11,591+0,871x
С увеличением выпуска продукции на 1 тыс. руб. затраты на производство увеличиваются на 0,871 млн. руб. в среднем, постоянные затраты равны 11,591 млн. руб.
2.1.2. Тесноту связи оценим с помощью линейного коэффициента парной корреляции.
Предварительно определим средние квадратические отклонения признаков.
Средние квадратические отклонения:
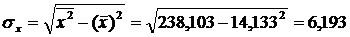
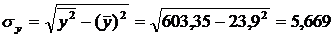
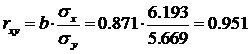
Между признаками X и Y наблюдается очень тесная линейная корреляционная связь.

2.1.3. Оценим качество построенной модели.
Определим коэффициент детерминации:
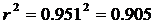
т. е. данная модель объясняет 90,5% общей дисперсии у, на долю необъясненной дисперсии приходится 9,5%.
Следовательно, качество модели высокое.
Найдем величину средней ошибки аппроксимации Аi .
Предварительно из уравнения регрессии определим теоретические значения 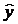 для каждого значения фактора.
для каждого значения фактора.
Ошибка аппроксимации Аi, i=1…15:
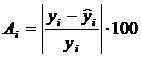
Средняя ошибка аппроксимации:
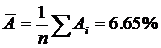
Ошибка небольшая, качество модели высокое.
2.1.4. Определим средний коэффициент эластичности:
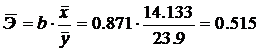
Он показывает, что с увеличением выпуска продукции на 1% затраты на производство увеличиваются в среднем на 0,515%.
2.1.5. Оценим статистическую значимость полученного уравнения.
Проверим гипотезу H0, что выявленная зависимость у от х носит случайный характер, т. е. полученное уравнение статистически незначимо. Примем α=0,05. Найдем табличное (критическое) значение F-критерия Фишера:
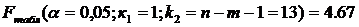
Найдем фактическое значение F— критерия Фишера:
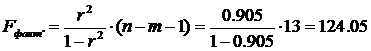
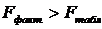
следовательно, гипотеза H0 отвергается, принимается альтернативная гипотеза H1: с вероятностью 1-α=0,95 полученное уравнение статистически значимо, связь между переменными x и y неслучайна.
Построим полученное уравнение.

2.2. Модель полулогарифмической парной регрессии.
2.2.1. Рассчитаем параметры а и b в регрессии:
Линеаризуем данное уравнение, обозначив:
Параметры a и b уравнения
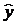 = a + bz
= a + bz
определяются методом наименьших квадратов:
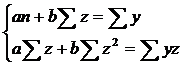
Рассчитываем таблицу 2.
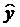
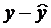
Разделив на n и решая методом Крамера, получаем формулу для определения b:
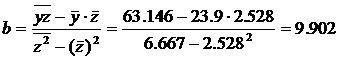
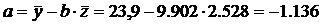
2.2.2. Оценим тесноту связи между признаками у и х.
Т. к. уравнение у = а + bln x линейно относительно параметров а и b и его линеаризация не была связана с преобразованием зависимой переменной _у, то теснота связи между переменными у и х, оцениваемая с помощью индекса парной корреляции Rxy, также может быть определена с помощью линейного коэффициента парной корреляции ryz
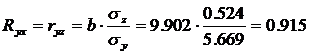
среднее квадратическое отклонение z:
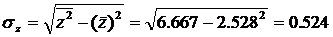
Значение индекса корреляции близко к 1, следовательно, между переменными у и х наблюдается очень тесная корреляционная связь вида = a + bz.
2.2.3. Оценим качество построенной модели.
Определим коэффициент детерминации:
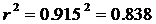 ,
,
т. е. данная модель объясняет 83,8% общей вариации результата у, на долю необъясненной вариации приходится 16,2%. Следовательно, качество модели высокое.
Найдем величину средней ошибки аппроксимации Аi .
Предварительно из уравнения регрессии определим теоретические значения 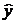 для каждого значения фактора. Ошибка аппроксимации Аi,:
для каждого значения фактора. Ошибка аппроксимации Аi,:
, i=1…15.
Средняя ошибка аппроксимации:
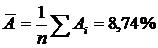 .
.
Ошибка небольшая, качество модели высокое.
2.2.4.Определим средний коэффициент эластичности:
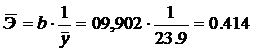
Он показывает, что с увеличением выпуска продукции на 1% затраты на производство увеличиваются в среднем на 0,414%.
2.2.5. Оценим статистическую значимость полученного уравнения.
Проверим гипотезу H0, что выявленная зависимость у от х носит случайный характер, т.е. полученное уравнение статистически незначимо. Примем α=0,05.
Найдем табличное (критическое) значение F-критерия Фишера:
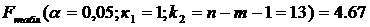
Найдем фактическое значение F-критерия Фишера:
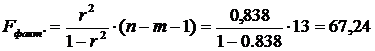
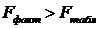
следовательно, гипотеза H0 отвергается, принимается альтернативная гипотеза H1: с вероятностью 1-α=0,95 полученное уравнение статистически значимо, связь между переменными x и y неслучайна.
Построим уравнение регрессии на поле корреляции
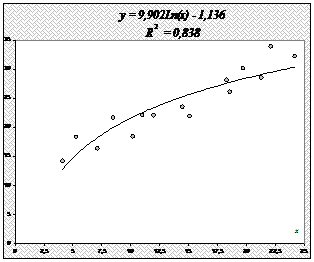
2.3. Модель степенной парной регрессии.
2.3.1. Рассчитаем параметры а и b степенной регрессии:
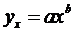
Расчету параметров предшествует процедура линеаризации данного уравнения:
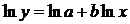
и замена переменных:
определяются методом наименьших квадратов:
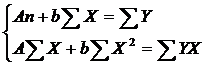
Рассчитываем таблицу 3.
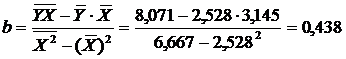
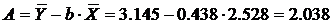
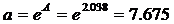
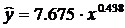
Построим уравнение регрессии на поле корреляции:
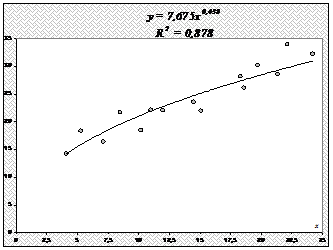
2.3.2. Оценим тесноту связи между признаками у и х с помощью индекса парной корреляции Ryx.
Предварительно рассчитаем теоретическое значение для каждого значения фактора x, и 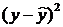 , тогда:
, тогда:
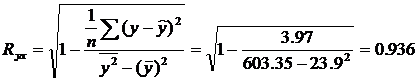
Значение индекса корреляции Rxy близко к 1, следовательно, между переменными у и х наблюдается очень тесная корреляционная связь вида: 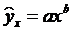
2.3.3. Оценим качество построенной модели.
Определим индекс детерминации:
т. е. данная модель объясняет 87,6% общей вариации результата у, а на долю необъясненной вариации приходится 12,4%.
Качество модели высокое.
Найдем величину средней ошибки аппроксимации.
Ошибка аппроксимации Аi, i=1…15:
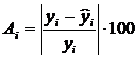
Средняя ошибка аппроксимации:
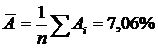
Ошибка небольшая, качество модели высокое.
2.3.4. Определим средний коэффициент эластичности:
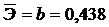
Он показывает, что с увеличением выпуска продукции на 1% затраты на производство увеличиваются в среднем на 0,438%.
2.3.5.Оценим статистическую значимость полученного уравнения.
Проверим гипотезу H0, что выявленная зависимость у от х носит случайный характер, т. е. полученное уравнение статистически незначимо. Примем α=0,05.
табличное (критическое) значение F-критерия Фишера:
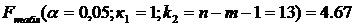
фактическое значение F-критерия Фишера:
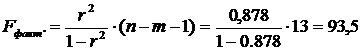
следовательно, гипотеза H0 отвергается, принимается альтернативная гипотеза H1: с вероятностью 1-α=0,95 полученное уравнение статистически значимо, связь между переменными x и y неслучайна.



