Метрики в машинном обучении: precision, recall и не только
Почему я это написал. Долгое время я был бэкэнд разработчиком. Вращался среди коллег и прекрасно их понимал. Но бэкенд нужен и людям, занимающимся машинным обучением. В какой-то момент я попал в их логово. И вот тут я поднял, что вообще не понимаю их язык. Думаю, что не только я оказывался в такой ситуации, поэтому сейчас расскажу всё понятными словами для нормальных людей.
Немного про машинное обучение
ML работает всего с несколькими вещами:
Приведу пример. Допустим у вас есть яблоня. Каждый год вы ломаете голову, опрыскивать ли её от долгоносика. Решили обучить модель, что она вам предсказывала нашествия долгоносика.
Данные: Допустим, вы знаете только весенние температуры в виде одного числа. (Не важно, что это, допустим, просто средняя температура.) То есть у вас есть одна фича — температура.
Разметка У вас есть журнал по годам, где отмечено, был долгоносик или нет. То есть каждой температуре вы можете сопоставить «правильный» ответ. Обратите внимание, что одной и той же температуре могут соответствовать несколько ответов, они могут быть разными (за разные годы).
Модель Пусть у нас будет модель с одним параметром: пограничной температурой. Модель будет просто говорить «да», если температура выше какой-то черты и «нет» — если ниже. Можно было бы придумать модель с двумя параметрами (она бы смотрела на интервал), или ещё сложнее, но мы сейчас возьмём самую простую, для наглядности.
Предсказания Если применить модель к температурам (фичам), то получим предсказания.
Немного кода
Чтобы было с чем играть, вот вам код. Тут есть и данные, и модель, и всё о чём мы будем говорить.
Если это запустить, то мы получим метрики для разных моделей:
T — это параметр модели. То есть мы получили метрики, фактически, для 10 разных моделей.
Если раскомментировать dump() то будет видна детальная информация.
Сейчас мы со всем разберёмся.
TP, TN, FP, FN и друге буквы
Когда люди начинают жонглировать этими буквами, с непривычки, можно очень легко запутаться и потерять нить. Чтобы всё встало на свои места, нам понадобится ещё несколько букв и пара полезных соотношений.
Давайте посмотрим на входные данные (разметку, фактические наблюдения). Введём две буквы:
Теперь посмотрим на прогнозы модели. Здесь тоже есть positive и negative, но их сразу же делят на четыре группы:
Тут важно проникнуться простыми соотношениями:
Остановитесь тут и подумайте минуту.
Ну и, конечно, ясно что такое TP+FP (это все ответы «да», полученные от модели) и NT+FN (все ответы «нет»).
Ценность метрик
У нас появились первые метрики. Давайте посмотрим, на сколько они полезны.
Аналогично не работают и другие три метрики. Нужно что-то получше.
Accuracy
Первое, что приходит в голову: давайте поделим все правильные ответы на все вообще ответы.
Такая метрика уже лучше, чем ничего, но всё же, она очень плоха. Даже в моём примере (хотя я не подгонял специально числа) видно, что, с одной стороны, разумные модели имеют высокую точность, однако, побеждает по точности просто самая пессимистичная модель.
Вы можете поиграться с данными и посмотреть, как это происходит. Но понять смысл очень просто на другом примере. Допустим вы хотите предсказывать землетрясения (какое-то очень редкое явление). Ясно, что по этой метрике всегда будет побеждать модель, которая даже не пытается ничего предсказывать, а просто говорит всегда «нет». Те же модели, которые будут пытаться говорить когда-то «да», будут иногда ошибаться в позитивных прогнозах и сразу же терять очки.
Поэтому, про эту метрику вы, скорее всего, даже не услышите никогда. Я тут её упомянул только чтобы показать её неэффективность при, кажущейся, логичности.
Precision, recall и их друзья
Лично я чаще всего сталкивался именно с этими словами. При том, что, как мне кажется, это самые неудачные варианты. Я буду приводить альтернативные называния, которые, как мне кажется, на много лучше отражают суть.
Recall aka sensitivity, hit rate, or true positive rate (TPR)
Мне кажется, hit rate и TPR лучше всего отражают суть. В этой метрике мы рассматриваем только P-случаи: когда в реальных наблюдениях было «да». И считаем, какую долю из этих случаев модель предсказала правильно.
Все случаи «нет» мы отбрасываем.
У recall есть брат-близнец:
Specificity, selectivity or true negative rate (TNR)
Важно, так же, заметить, что если T и P сильно отличаются (как в примере с землетрясениями), то сравнивать recall и специфичность надо очень осторожно.
Precision aka positive predictive value (PPV)
Какая часть наших предсказаний «да» действительно сбылась:
Недостатки этой метрики аналогичны: она вообще никак не учитывает предсказания «нет». Из наших результатов видно, что побеждает модель, которая почти всегда говорить «нет». Она как бы снижает риск проиграть, выводя большую часть своих ответ за рамки рассмотрения.
У этой метрики есть аналогичный близнец
Negative predictive value (NPV)
Какая часть «нет»-предсказаний сбылась.
И ещё немного метрик
Перечислю кратко и другие метрики. Это далеко не все существующие, а просто аналоги вышеперечисленных, только относительно отрицательных прогнозов.
Miss rate aka false negative rate (FNR)
Fall-out aka false positive rate (FPR)
False discovery rate (FDR)
False omission rate (FOR)
И что же со всем этим делать
Как вы уже видели, каждая из этих метрик рассматривает только какое-то подмножество предсказаний. Поэтому их эффективность очень сомнительна.
Однако, их очень часто используют для двух вещей:
На втором я хотел бы остановиться в некотором философском ключе.
Давайте задумаемся, а что значит «одна модель лучше другой»? Единого ответа тут нет.
В нашем примере с долгоносиком всё зависит от наших приоритетов.
Если мы хотим ни в коем случае не потерять урожай, то нам надо максимизировать TP любой ценой. Фактически, в предельном случае, мы можем выкинуть любые модели и просто опрыскивать дерево химикатами всегда.
В реальной же жизни, мы ищем некоторый компромисс. Во многих случаях он может быть совершенно чётко сформулирован, с учётом цен на химикаты, стоимости урожая, репутационных потерь и прочего.
Не редко, люди придумывают собственные метрики. Но есть и готовые, пригодные во многих случаях.
F1-score
Это комбинация recall и precision:
Но мне кажется, поведение этой функции становится гораздо понятней, если записать её так:
То есть, это гармоническое среднее.
Максимальный F1-score мы получим, если и recall, и precision достаточно далеки от нуля. Он позволяет найти некое компромиссное решение, фактически, между максимизацией TP по разным шкалам.
Это не единственная возможная метрика. И у неё, как вы видите, тоже есть чёткий фокус, а значит и недостатки. Однако, даже её достаточно, чтобы среди наших моделей выиграла та, у которой пограничная температура равна 4. Давайте ещё раз взглянем на сравнение всех моделей:
И вот детализация по этой конкретной модели (с T=4):
Вы можете взять мой код, раскомментировать функцию dump() и посмотреть детализацию по всем моделям.
Надеюсь, я пролил некоторый свет на вопрос.
Оценка моделей ML/DL: матрица ошибок, Accuracy, Precision и Recall
В компьютерном зрении обнаружение объекта — это проблема определения местоположения одного или нескольких объектов на изображении. Помимо традиционных методов обнаружения, продвинутые модели глубокого обучения, такие как R-CNN и YOLO, могут обеспечить впечатляющие результаты при различных типах объектов. Эти модели принимают изображение в качестве входных данных и возвращают координаты прямоугольника, ограничивающего пространство вокруг каждого найденного объекта.
В этом руководстве обсуждается матрица ошибок и то, как рассчитываются precision, recall и accuracy метрики.
Здесь мы рассмотрим:
Матрица ошибок для бинарной классификации
В бинарной классификации каждая выборка относится к одному из двух классов. Обычно им присваиваются такие метки, как 1 и 0, или положительный и отрицательный (Positive и Negative). Также могут использоваться более конкретные обозначения для классов: злокачественный или доброкачественный (например, если проблема связана с классификацией рака), успех или неудача (если речь идет о классификации результатов тестов учащихся).
Такие наименования нужны в первую очередь для того, чтобы нам, людям, было проще различать классы. Для модели более важна числовая оценка. Обычно при передаче очередного набора данных на выходе вы получите не метку класса, а числовой результат. Например, когда эти семь семплов вводятся в модель, каждому классу будут назначены следующие значения:
На основании полученных оценок каждой выборке присваивается соответствующий класс. Такое преобразование числовых результатов в метки происходит с помощью порогового значения. Данное граничное условие является гиперпараметром модели и может быть определено пользователем. Например, если порог равен 0.5, тогда любая оценка, которая больше или равна 0.5, получает положительную метку. В противном случае — отрицательную. Вот предсказанные алгоритмом классы:
Сравните достоверные и полученные метки — мы имеем 4 верных и 3 неверных предсказания. Стоит добавить, что изменение граничного условия отражается на результатах. Например, установка порога, равного 0.6, оставляет только два неверных прогноза.
Для получения дополнительной информации о характеристиках модели используется матрица ошибок (confusion matrix). Матрица ошибок помогает нам визуализировать, «ошиблась» ли модель при различении двух классов. Как видно на следующем рисунке, это матрица 2х2. Названия строк представляют собой эталонные метки, а названия столбцов — предсказанные.
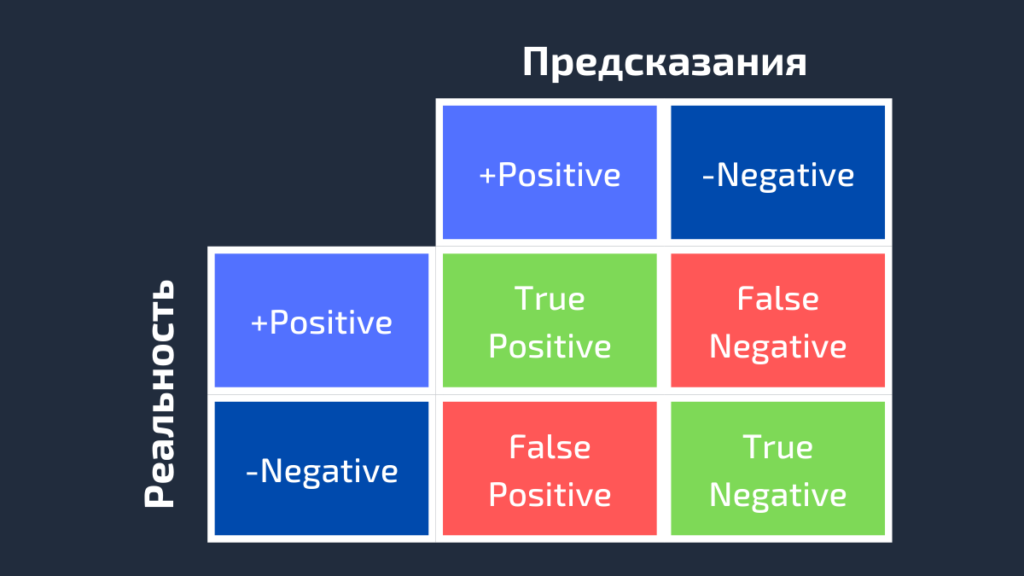
Четыре элемента матрицы (клетки красного и зеленого цвета) представляют собой четыре метрики, которые подсчитывают количество правильных и неправильных прогнозов, сделанных моделью. Каждому элементу дается метка, состоящая из двух слов:
True, если получено верное предсказание, то есть эталонные и предсказанные метки классов совпадают, и False, когда они не совпадают. Positive или Negative — названия предсказанных меток.
Таким образом, всякий раз, когда прогноз неверен, первое слово в ячейке False, когда верен — True. Наша цель состоит в том, чтобы максимизировать показатели со словом «True» (True Positive и True Negative) и минимизировать два других (False Positive и False Negative). Четыре метрики в матрице ошибок представляют собой следующее:
Мы можем рассчитать эти четыре показателя для семи предсказаний, использованных нами ранее. Полученная матрица ошибок представлена на следующем рисунке.
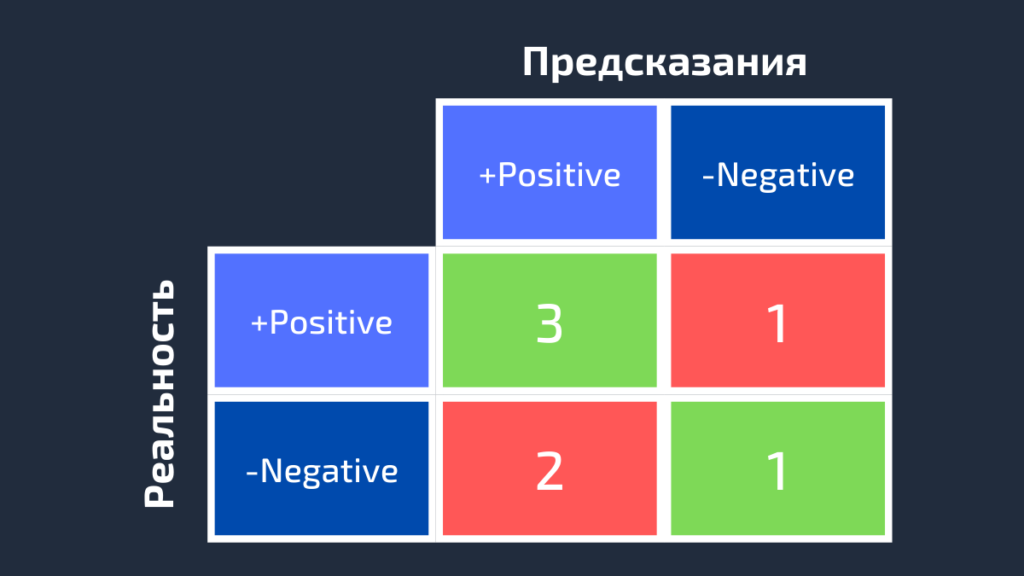
Вот так вычисляется матрица ошибок для задачи двоичной классификации. Теперь посмотрим, как решить данную проблему для большего числа классов.
Матрица ошибок для мультиклассовой классификации
Что, если у нас более двух классов? Как вычислить эти четыре метрики в матрице ошибок для задачи мультиклассовой классификации? Очень просто!
Предположим, имеется 9 семплов, каждый из которых относится к одному из трех классов: White, Black или Red. Вот достоверные метки для 9 выборок:
После загрузки данных модель делает следующее предсказание:
Для удобства сравнения здесь они расположены рядом.
Перед вычислением матрицы ошибок необходимо выбрать целевой класс. Давайте назначим на эту роль класс Red. Он будет отмечен как Positive, а все остальные отмечены как Negative.
11111111111111111111111После замены остались только два класса (Positive и Negative), что позволяет нам рассчитать матрицу ошибок, как было показано в предыдущем разделе. Стоит заметить, что полученная матрица предназначена только для класса Red.
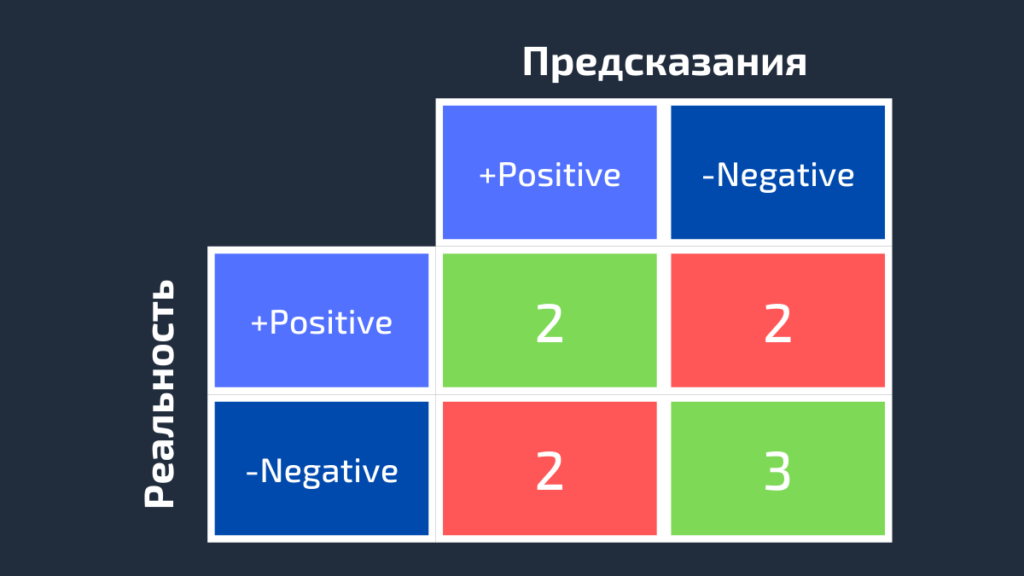
Далее для класса White заменим каждое его вхождение на Positive, а метки всех остальных классов на Negative. Мы получим такие достоверные и предсказанные метки:
На следующей схеме показана матрица ошибок для класса White.
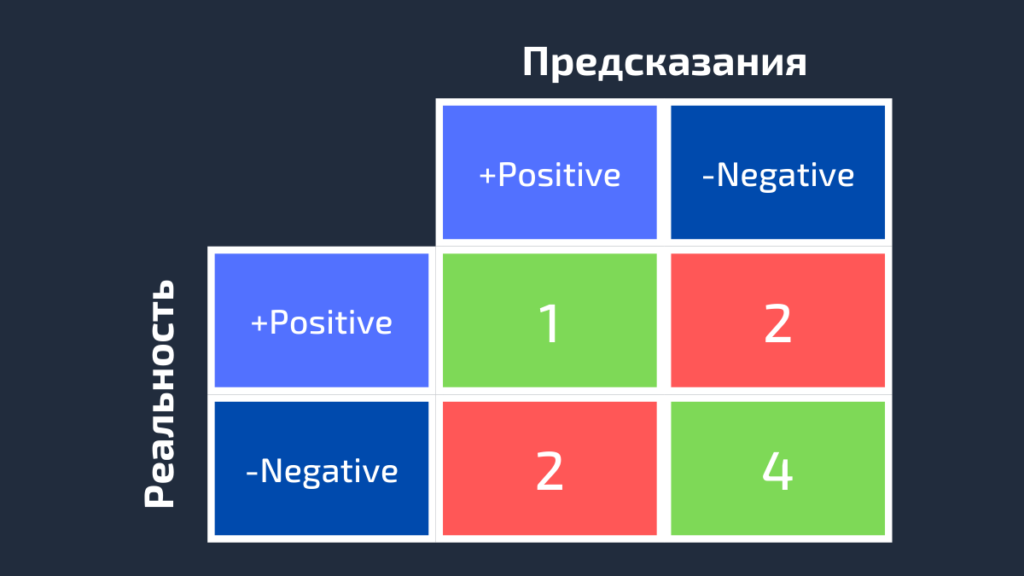
Точно так же может быть получена матрица ошибок для Black.
Расчет матрицы ошибок с помощью Scikit-Learn
Следующий код вычисляет матрицу ошибок для примера двоичной классификации, который мы обсуждали ранее.
Обратите внимание, что порядок метрик отличается от описанного выше. Например, показатель True Positive находится в правом нижнем углу, а True Negative — в верхнем левом углу. Чтобы исправить это, мы можем перевернуть матрицу.
В оставшейся части этого текста мы сосредоточимся только на двух классах. В следующем разделе обсуждаются три ключевых показателя, которые рассчитываются на основе матрицы ошибок.
Accuracy, Precision и Recall
Как мы уже видели, матрица ошибок предлагает четыре индивидуальных показателя. На их основе можно рассчитать другие метрики, которые предоставляют дополнительную информацию о поведении модели:
В следующих подразделах обсуждается каждый из этих трех показателей.
Метрика Accuracy
Accuracy — это показатель, который описывает общую точность предсказания модели по всем классам. Это особенно полезно, когда каждый класс одинаково важен. Он рассчитывается как отношение количества правильных прогнозов к их общему количеству.
Рассчитаем accuracy с помощью Scikit-learn на основе ранее полученной матрицы ошибок. Переменная acc содержит результат деления суммы True Positive и True Negative метрик на сумму всех значений матрицы. Таким образом, accuracy, равная 0.5714, означает, что модель с точностью 57,14% делает верный прогноз.
Стоит учесть, что метрика accuracy может быть обманчивой. Один из таких случаев — это несбалансированные данные. Предположим, у нас есть всего 600 единиц данных, из которых 550 относятся к классу Positive и только 50 — к Negative. Поскольку большинство семплов принадлежит к одному классу, accuracy для этого класса будет выше, чем для другого.
Если модель сделала 530 правильных прогнозов из 550 для класса Positive, по сравнению с 5 из 50 для Negative, то общая accuracy равна (530 + 5) / 600 = 0.8917. Это означает, что точность модели составляет 89.17%. Полагаясь на это значение, вы можете подумать, что для любой выборки (независимо от ее класса) модель сделает правильный прогноз в 89.17% случаев. Это неверно, так как для класса Negative модель работает очень плохо.
Precision
Precision представляет собой отношение числа семплов, верно классифицированных как Positive, к общему числу выборок с меткой Positive (распознанных правильно и неправильно). Precision измеряет точность модели при определении класса Positive.
Когда модель делает много неверных Positive классификаций, это увеличивает знаменатель и снижает precision. С другой стороны, precision высока, когда:
Представьте себе человека, который пользуется всеобщим доверием; когда он что-то предсказывает, окружающие ему верят. Метрика precision похожа на такого персонажа. Если она высока, вы можете доверять решению модели по определению очередной выборки как Positive. Таким образом, precision помогает узнать, насколько точна модель, когда она говорит, что семпл имеет класс Positive.
Основываясь на предыдущем обсуждении, вот определение precision:
Precision отражает, насколько надежна модель при классификации Positive-меток.
На следующем изображении зеленая метка означает, что зеленый семпл классифицирован как Positive, а красный крест – как Negative. Модель корректно распознала две Positive выборки, но неверно классифицировала один Negative семпл как Positive. Из этого следует, что метрика True Positive равна 2, когда False Positive имеет значение 1, а precision составляет 2 / (2 + 1) = 0.667. Другими словами, процент доверия к решению модели, что выборка относится к классу Positive, составляет 66.7%.
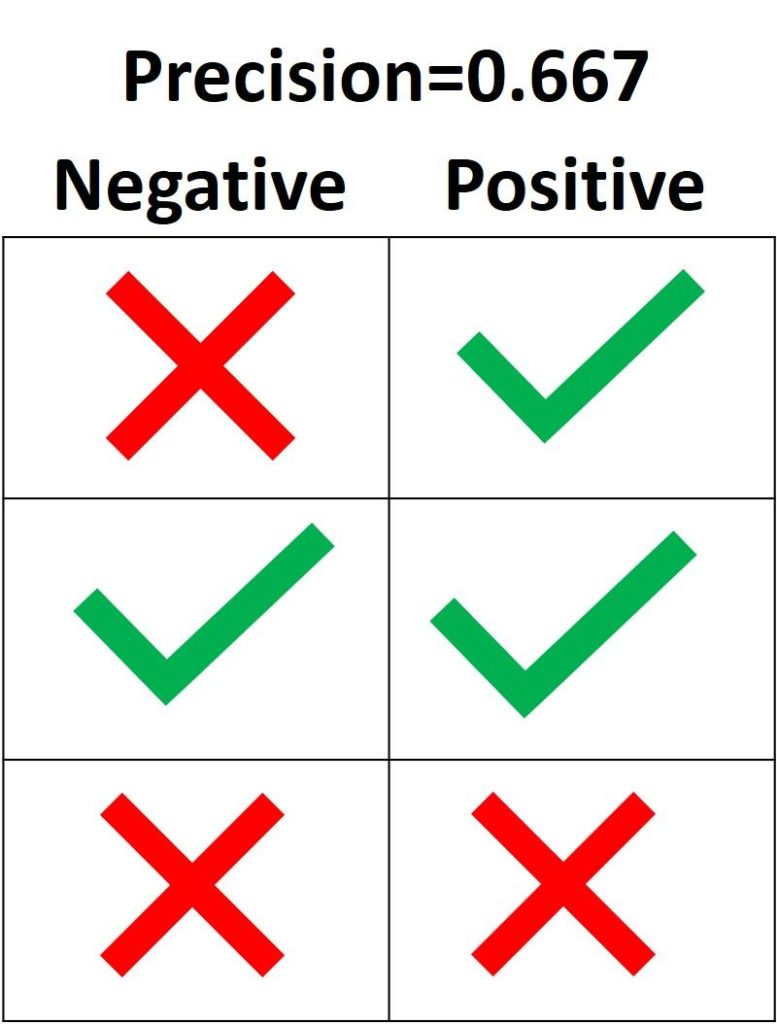
Цель precision – классифицировать все Positive семплы как Positive, не допуская ложных определений Negative как Positive. Согласно следующему рисунку, если все три Positive выборки предсказаны правильно, но один Negative семпл классифицирован неверно, precision составляет 3 / (3 + 1) = 0.75. Таким образом, утверждения модели о том, что выборка относится к классу Positive, корректны с точностью 75%.
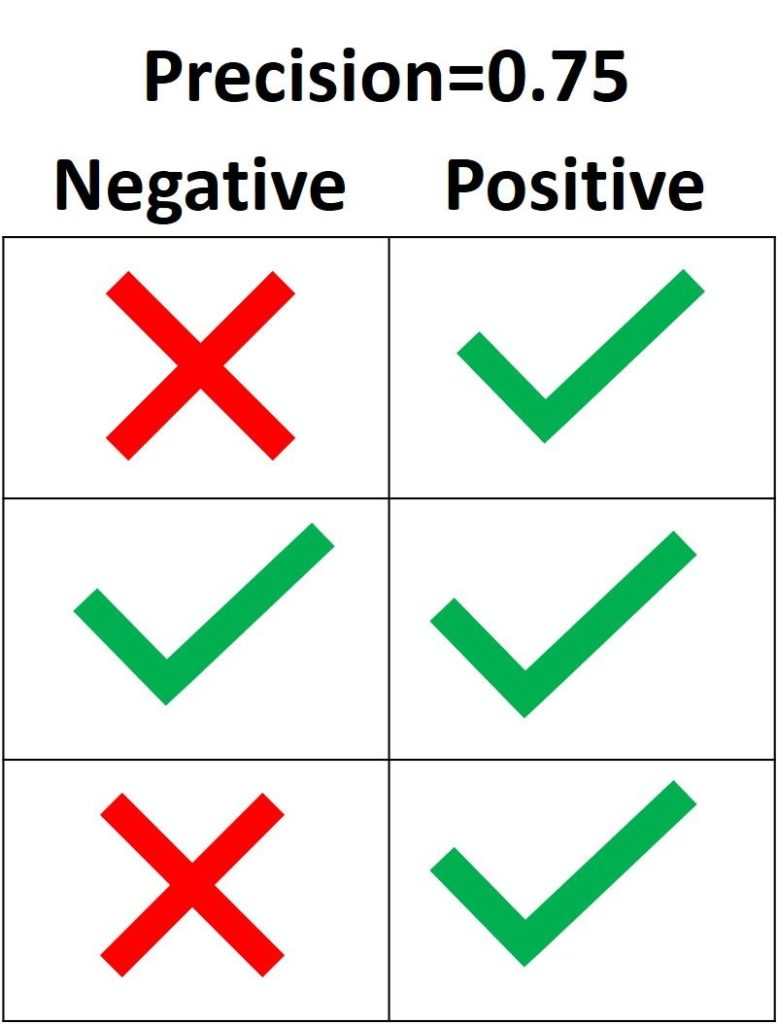
Единственный способ получить 100% precision — это классифицировать все Positive выборки как Positive без классификации Negative как Positive.
Recall
Recall рассчитывается как отношение числа Positive выборок, корректно классифицированных как Positive, к общему количеству Positive семплов. Recall измеряет способность модели обнаруживать выборки, относящиеся к классу Positive. Чем выше recall, тем больше Positive семплов было найдено.
Recall заботится только о том, как классифицируются Positive выборки. Эта метрика не зависит от того, как предсказываются Negative семплы, в отличие от precision. Когда модель верно классифицирует все Positive выборки, recall будет 100%, даже если все представители класса Negative были ошибочно определены как Positive. Давайте посмотрим на несколько примеров.
На следующем изображении представлены 4 разных случая (от A до D), и все они имеют одинаковый recall, равный 0.667. Представленные примеры отличаются только тем, как классифицируются Negative семплы. Например, в случае A все Negative выборки корректно определены, а в случае D – наоборот. Независимо от того, как модель предсказывает класс Negative, recall касается только семплов относящихся к Positive.

Из 4 случаев, показанных выше, только 2 Positive выборки определены верно. Таким образом, метрика True Positive равна 2. False Negative имеет значение 1, потому что только один Positive семпл классифицируется как Negative. В результате recall будет равен 2 / (2 + 1) = 2/3 = 0.667.
Поскольку не имеет значения, как предсказываются объекты класса Negative, лучше их просто игнорировать, как показано на следующей схеме. При расчете recall необходимо учитывать только Positive выборки.

Что означает, когда recall высокий или низкий? Если recall имеет большое значение, все Positive семплы классифицируются верно. Следовательно, модели можно доверять в ее способности обнаруживать представителей класса Positive.
На следующем изображении recall равен 1.0, потому что все Positive семплы были правильно классифицированы. Показатель True Positive равен 3, а False Negative – 0. Таким образом, recall вычисляется как 3 / (3 + 0) = 1. Это означает, что модель обнаружила все Positive выборки. Поскольку recall не учитывает, как предсказываются представители класса Negative, могут присутствовать множество неверно определенных Negative семплов (высокая False Positive метрика).

С другой стороны, recall равен 0.0, если не удается обнаружить ни одной Positive выборки. Это означает, что модель обнаружила 0% представителей класса Positive. Показатель True Positive равен 0, а False Negative имеет значение 3. Recall будет равен 0 / (0 + 3) = 0.
Когда recall имеет значение от 0.0 до 1.0, это число отражает процент Positive семплов, которые модель верно классифицировала. Например, если имеется 10 экземпляров Positive и recall равен 0.6, получается, что модель корректно определила 60% объектов класса Positive (т.е. 0.6 * 10 = 6).
Подобно precision_score(), функция repl_score() из модуля sklearn.metrics вычисляет recall. В следующем блоке кода показан пример ее использования.
После определения precision и recall давайте кратко подведем итоги:
Некоторые вопросы для проверки понимания:
Precision или Recall?
Решение о том, следует ли использовать precision или recall, зависит от типа вашей проблемы. Если цель состоит в том, чтобы обнаружить все positive выборки (не заботясь о том, будут ли negative семплы классифицированы как positive), используйте recall. Используйте precision, если ваша задача связана с комплексным предсказанием класса Positive, то есть учитывая Negative семплы, которые были ошибочно классифицированы как Positive.
Представьте, что вам дали изображение и попросили определить все автомобили внутри него. Какой показатель вы используете? Поскольку цель состоит в том, чтобы обнаружить все автомобили, используйте recall. Такой подход может ошибочно классифицировать некоторые объекты как целевые, но в конечном итоге сработает для предсказания всех автомобилей.
Теперь предположим, что вам дали снимок с результатами маммографии, и вас попросили определить наличие рака. Какой показатель вы используете? Поскольку он обязан быть чувствителен к неверной идентификации изображения как злокачественного, мы должны быть уверены, когда классифицируем снимок как Positive (то есть с раком). Таким образом, предпочтительным показателем в данном случае является precision.
Вывод
В этом руководстве обсуждалась матрица ошибок, вычисление ее 4 метрик (true/false positive/negative) для задач бинарной и мультиклассовой классификации. Используя модуль metrics библиотеки Scikit-learn, мы увидели, как получить матрицу ошибок в Python.
Немного о Precision и Recall
FRD и нефункциональные требования
Зачастую в практике системного аналитика, составляющего FRD, встречаются вещи неформализуемые. Примером могут быть требования типа:
Такие требования, будучи записанными в FRD «как есть», являются чудовищным источником проблем впоследствии. Формализация таких требований — постоянная головная боль аналитика. Обычно аналитик решает задачу в два приема: сначала выдвигается «эквивалентное» формальное требование, затем в процессе общения (с заказчиком, экспертом предметной области и т.п.) доказывается, что такое формальное требование может заменить собой исходное требование. Вообще говоря, полученное нами требование не является функциональным; оно описывает не «что» должна уметь делать система, а «как делать». При этом «как делать» должно быть сформулировано с конкретной качественной характеристикой.
Это была преамбула к тезису о том, что системный аналитик должен хорошо владеть математическим аппаратом и заодно уметь объяснять «математику» заказчику. А теперь рассмотрим пример.
О задаче классификации
Предположим, что мы пишем FRD для системы контекстной рекламы, похожей на Amazon Omakase. Одним из модулей нашей будущей системы будет контекстный анализатор:

Анализатор принимает на входе текст веб-страницы и производит его контекстный анализ. То, каким образом он это делает, нас особо не интересует; важно, что на выходе мы получаем набор товарных категорий (множество которых заранее определено). Далее на основе этих категорий мы можем показывать баннеры, товарные ссылки (как Amazon) и т.п. Анализатор для нас пока является черным ящиком, которому мы можем задать вопрос (в виде текста документа) и получить ответ.
Заказчик хочет, чтобы анализатор «хорошо определял контекст». Нам надо сформулировать, что это требование означает. Для начала поговорим о контексте как таковом, т.е. о том самом наборе категорий, который возвращается анализатором. Можно определить это как задачу классификации, когда документу (веб-странице) сопоставляется множество классов из заранее определенного числа; в нашем случае классы — это товарные категории. Задача классификации довольно часто встречается в обработке текстов (например, спам-фильтры).
Метрики оценки
Рассмотрим метрики оценки, применимые к задаче классификации. Допустим, что мы знаем правильные категории для некоторого числа документов. Сгруппируем ответы нашего гипотетического анализатора следующим образом:
Назовем тестовой выборкой множество документов (веб-страниц), для которых мы знаем правильные ответы. Если подсчитать по каждой категории число попаданий (считаем попадания по парам документ — категория), получим каноническую табличку распределения ответов:
| Ожидалось | ||
|---|---|---|
| Получили | tp (true positive) | fp (false positive) |
| fn (false negative) | tn (true negative) | |
Левая колонка таблицы — это «правильные» сочетания документов и категорий (присутствия которых мы ожидаем на выходе), правая — неправильные. Верхняя строка таблицы — положительные (positive) ответы классификатора, нижняя — отрицательные (в нашем случае — отсутствие категории в ответе). Если число всех пар документ — категория равно N, то нетрудно увидеть, что 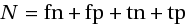
| Таблица распределения (contingency matrix) дает несколько иной взгляд на оценку качества нашего классификатора, нежели просто подсчет правильных и неправильных ответов. Здесь обозначено целых 4 непересекающихся класса ответов, множества которых можно изобразить на картинке. Здесь зеленые области обозначают правильные ответы, красные — неправильные. Весь прямоугольник целиком соответствует нашей выборке из N пар. | 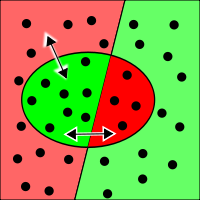 |
В общем-то, теперь можно записать требование заказчика в виде 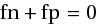 (число неправильных ответов равно нулю) и на этом остановиться. Однако на практике таких систем не бывает и анализатор будет, разумеется, работать с ошибками относительно тестовой выборки. Понять процент ошибок нам поможет метрика правильности (accuracy):
(число неправильных ответов равно нулю) и на этом остановиться. Однако на практике таких систем не бывает и анализатор будет, разумеется, работать с ошибками относительно тестовой выборки. Понять процент ошибок нам поможет метрика правильности (accuracy): 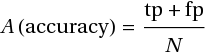
В числителе мы видим диагональ матрицы — суммарное число правильных ответов, который делится на общее число вопросов. Например, анализатор, давший 9 правильных ответов из 10 возможных, имеет accuracy 90%.
Метрика F1
Простым примером неприменимости accuracy-метрики является задача определения обувного бренда. Допустим, мы хотим подсчитать число упоминаний обувных брендов в тексте. Рассмотрим задачу классификации, целью которой будет определить, является ли указанная сущность обувным брендом (Timberland, Columbia, Ted Baker, Ralph Lauren и т.п.). Иначе говоря, мы разбиваем сущности в тексте на два класса: A — Обувной бренд, B — Все остальное.
Теперь рассмотрим вырожденный классификатор, который просто возвращает класс B (Все остальное) для любых сущностей. Для этого классификатора число истинно-положительных ответов будет равно 0. Вообще говоря, давайте подумаем на тему, а часто ли при чтении текста в интернете нам встречаются обувные бренды? Оказывается, как ни странно, что в общем случае 99.9999% слов текста не являются обувными брендами. Построим матрицу распределения ответов для выборки в 100.000:
| Ожидалось | ||
|---|---|---|
| Получили | tp = 0 | fp = 0 |
| fn = 10 | tn = 99990 | |
Вычислим его accuracy, который будет равен 99990 / 100000 = 99.99%! Итак, мы легко построили классификатор, который по сути не делает ничего, однако имеет огромный процент правильных ответов. В то же время совершенно понятно, что задачу определения обувного бренда мы не решили. Дело в том, что правильные сущности в нашем тексте сильно «разбавлены» другими словами, которые для классификации никакого значения не имеют. Учитывая этот пример, вполне понятно желание использовать другие метрики. Например, значение tn явно является «мусорным» — оно вроде как означает правильный ответ, но разрастание tn в итоге сильно «подавляет» вклад tp (который нам важен) в формулу accuracy.
Определим меру точности (P, precision) как:
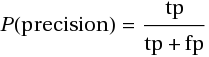
Как нетрудно заметить, мера точности характеризует, сколько полученных от классификатора положительных ответов являются правильными. Чем больше точность, тем меньше число ложных попаданий.
Мера точности, однако, не дает представление о том, все ли правильные ответы вернул классификатор. Для этого существует так называемая мера полноты (R, recall):
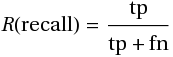
Мера полноты характеризует способность классификатора «угадывать» как можно большее число положительных ответов из ожидаемых. Заметим, что ложно-положительные ответы никак не влияют на эту метрику.
Precision и Recall дают довольно исчерпывающую характеристику классификатора, причем «с разных углов». Обычно при построении подобного рода систем приходится все время балансировать между двумя этими метриками. Если вы пытаетесь повысить Recall, делая классификатор более «оптимистичным», это приводит к падению Precision из-за увеличения числа ложно-положительных ответов. Если же вы подкручиваете свой классификатор, делая его более «пессимистичным», например, строже фильтруя результаты, то при росте Precision это вызовет одновременное падение Recall из-за отбраковки какого-то числа правильных ответов. Поэтому удобно для характеристики классификатора использовать одну величину, так называемую метрику F1:
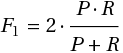
Фактически это просто среднее гармоническое величин P и R. Метрика F1 достигает своего максимума 1 (100%), если P = R = 100%.
(нетрудно прикинуть, что для нашего вырожденного классификатора F1 = 0). Величина F1 является одной из самых распространенных метрик для подобного рода систем. Именно F1 мы и будем использовать, чтобы сформулировать пороговое качество нашего анализатора в FRD.
В вычислении F1 для задачи классификации есть два основных подхода.
Зачем нужен второй способ? Дело в том, что размеры выборки для разных классов могут сильно различаться. Для каких-то классов у нас может быть очень мало примеров, а для каких-то — много. В итоге метрики одного «большого» класса, будучи сведенными в одну общую таблицу, будут «забивать» все остальные. В ситуации, когда мы хотим оценить качество работы системы более-менее равномерно для всех классов, второй вариант подходит лучше.
Обучающая и тестовая выборка
Выше мы рассматривали классификацию на единой выборке, для которой нам известны все ответы. Если применить это к контекстному анализатору, который мы пытаемся описать, все выглядит немного сложнее.
Прежде всего, мы должны зафиксировать товарные категории. Ситуация, когда мы гарантируем какую-то величину F1, а набор классов при этом может неограниченно расширяться, практически тупиковая. Поэтому дополнительно оговаривается, что набор категорий фиксирован.
Мы вычисляем значение F1 по заданной выборке, которая известна заранее. Эта выборка обычно называется обучающей. Однако мы не знаем, как поведет себя классификатор на тех данных, которые нам неизвестны. Для этих целей обычно используется так называемая тестовая выборка, иногда называемая golden set. Разница между обучающей и тестовой выборкой чисто умозрительная: ведь имея некоторое множество примеров, мы можем разрезать его на обучающую и тестовую выборку как нам угодно. Но для самообучающихся систем формирование правильной обучающей выборки очень критично. Неправильно подобранные примеры могут сильно повлиять на качество работы системы.
Типична ситуация, когда классификатор показывает хороший результат на обучающей выборке и совершенно провальный — на тестовой выборке. Если наш алгоритм классификации основан на машинном обучении (т.е. зависит от обучающей выборки), мы можем оценить его качество по более сложной «плавающей» схеме. Для этого все имеющиеся у нас примеры делим, скажем, на 10 частей. Изымаем первую часть и используем ее для обучения алгоритма; оставшиеся 90% примеров используем как тестовую выборку и вычисляем значение F1. Затем изымаем вторую часть и используем в качестве обучающей; получаем другое значение F1, и т.д. В итоге мы получили 10 значений F1, теперь берем их среднее арифметическое значение, которое и станет окончательным результатом. Повторюсь, что это способ (называемый также cross-fold validation) имеет смысл только для алгоритмов, основанных на машинном обучении.
Возвращаясь к написанию FRD, замечаем, что у нас ситуация куда хуже. Мы имеем потенциально неограниченный набор входных данных (все веб-страницы интернета) и нет никакого способа оценить контекст страницы, кроме как участие человека. Таким образом, наша выборка может быть сформирована только вручную, причем сильно зависеть от капризов составителя (а решение о том, отнести ли страницу к какой-то категории, принимает человек). Мы можем оценить меру F1 на известных нам примерах, но никак не можем узнать F1 для всех страниц интернета. Поэтому для потенциально неограниченных наборах данных (таких, как веб-страницы, коих неисчислимо много), иногда используют «метод тыка» (unsupervised). Для этого случайным образом выбирают определенное число примеров (страниц) и по ним оператор (человек) составляет правильный набор категорий (классов). Затем мы можем испытать классификатор на этих выбранных примерах. Далее, считая, что выбранные нами примеры являются типичными, мы можем приближенно оценить точность алгоритма (Precision). При этом Recall мы оценить не можем (неизвестно, сколько правильных ответов находятся за пределами выбранных нами примеров), следовательно, не можем вычислить и F1.
Таким образом, если мы хотим узнать, как ведет себя алгоритм на всех возможных входных данных, самое лучшее, что сможем оценить в этой ситуации — это приближенное значение Precision. Если же все согласны использовать заранее определенную фиксированную выборку, то можно вычислить средние значение F1 по этой выборке.
В итоге?
А в итоге нам придется сделать следующее:
Как видим, написать FRD на такую систему нелегко (особенно последний пункт), но возможно. Что касается порогового значения F1, в таких случаях можно отталкиваться от значений F1 для похожих задач классификации.
Пост был опубликован: Среда, Июнь 6th, 2012 в 6:14 пп



