Отказоустойчивая работа с Redis
Эта статья — переработанная версия доклада Отказоустойчивая работа с Redis с прошедшего 17 октября 2020 митапа PHP-разработчиков Йошкар-Олы.
Мы поговорим о подводных камнях использования Redis в системе, где важна отказоустойчивость — на примере хранения сессий в условном веб-сервисе, написанном на PHP, но многие замечания будут справедливы и для других платформ — например для микросервисов на Go. Статья будет полезна, если вы проектируете микросервисы или монолитные приложения с достаточно большой нагрузкой и интенсивно работаете с Redis либо столкнулись с потребностью в перепроектировании механизмов аутентификации и сессий.
Немного о Redis
Redis — это NoSQL СУБД с открытым исходным кодом, работающая с данными вида «ключ — значение». Если вы захотите узнать о преимуществах Redis, вы наверняка найдёте примерно такой список:
Redis хранит все данные в оперативной памяти, что повышает производительность
В Redis нет SQL и схемы хранилища, что опять же повышает производительность (нет интерпретатора SQL) и даёт гибкость
Нет никаких ACID транзакций, изменения просто сохраняются на диск в фоне, что тоже повышает производительность
Иначе говоря, Redis может быть очень быстрым.
Но давайте взглянем на это с точки зрения надёжности и отказоустойчивости:
Redis хранит все данные в оперативной памяти, и при аварийном завершении процесса или выключении машины данные будут потеряны
Redis не ориентирован на ACID транзакции, и на практике значит:
даже при включённом сохранении на диск данные могут быть потеряны частично либо полностью
в данных может быть нарушена целостность с точки зрения приложения
фоновое сохранение данных на диск может нанести ущерб производительности и отказоустойчивости
Значит ли это, что Redis плох? Вовсе нет. Наша статья о том, что при внедрении Redis в проект нужно рассматривать разные варианты и принимать взвешенные решения, а не верить слепо, что всё уже предусмотрено умными дядьками и никаких проблем на production не возникнет.
Теперь поговорим про это подробнее.
Сценарии отказа Redis
Допустим, мы используем классический метод развёртывания веб-приложений, и у нас есть две машины — на одной развёрнуто PHP приложение, на другой — Redis.
Ожидание в очереди

Из этих шагов только последний работает с той фантастической скоростью, которую обещают разработчики Redis. Все остальные могут вызывать проблемы.
Во-первых, Redis может упасть:
В этом случае приложение попытается установить соединение, но не сможет (сразу либо после произвольного таймаута, установленного для библиотеки Predis). Будет создано исключение, к которому код может быть не готов.
Во-вторых, может нарушиться сетевая связность:
В этом случае бесполезное ожидание и отказ по таймауту неизбежны, что может привести к веерным отказам: сначала бесполезные таймауты под нагрузкой приведут к повышению числа активных процессов php-fpm и числа соединений с СУБД, а потом закончится либо одно, либо другое, клиенты начнут получать 500-е и 504-е коды ошибок — сервис перестанет их обслуживать.
В-третьих, под высокой нагрузкой Redis может не успеть обработать полученную команду:
С точки зрения приложения произойдёт отказ по таймауту, с рисками веерного отказа. Что ещё хуже, веерные отказы могут произойти и без явных отказов Redis: приложение просто будет ждать дольше обычного и исчерпаются соединения с СУБД либо процессы php-fpm.
Наконец, у Redis может кончиться память, и тогда всё зависит от настроек maxmemory и maxmemory-policy. По умолчанию maxmemory-policy имеет значение noeviction, и это означает, что при нехватке памяти Redis перейдёт в режим readonly:
Даже если поменять maxmemory-policy, вы можете получить ситуацию, когда при нехватке памяти Redis выкидывает ключи, значительно сокращая время жизни сессий, токенов и других полезных данных. Будет ли ваше приложение работать нормально, если контракт на время жизни данных не выполняется?
Сценарии отказа Redis в Kubernetes
Давайте сгустим краски ещё больше: добавим Kubernetes и засунем в него Redis.
Kubernetes — это система управления кластером. Он запускает N приложений в контейнерах на меньшем числе машин, распределяя нагрузку такими сложными путями, что для сопровождения проекта в Kubernetes вам потребуется отдельная команда (если у вас всё кросс-функциональное, тогда её размажет ровным слоем по остальным командам).
Допустим, у нас есть кластер из 4 worker’ов, управляемых Kubernetes. Допустим, Kubernetes раскидал экземпляры PHP-приложения и Redis так, как показано на картинке:
После этого worker #3 вывели на обслуживание, в результате мы теряем единственный экземпляр Redis и 2 из 4 экземпляров приложения и получаем кратковременный отказ. Если Redis прислал свои данные не на сетевой диск, то получаем ещё и потерю всех его данных. Если же он писал на сетевой диск, то делал это медленно, поскрипывая винчестерами на весь дата-центр и мешая дежурным спать.
Как бы развернуть Redis, чтобы потеря одной worker-машины не создавала проблем?
У Redis предусмотрено два способа организации отказоустойчивости: Redis Sentinel и Redis Cluster. Прочитав документацию и собрав факты, вы увидите следующее:
Обе реализации являются скорее кирпичиками для построения отказоустойчивости с автоматическим failover
Redis Cluster имеет некоторую автоматизацию, но эта разница нивелируется в Kubernetes за счёт Redis Operator (например, spotahome/redis-operator), который основан на Redis Sentinel
Redis Cluster даёт шардирование, Redis Sentinel его не даст
Если вы хотите производительность выше той космической, что можно выжать из одного инстанса, подумайте о Redis Cluster вне Kubernetes. Если вы хотите засунуть Redis в Kuberntes, используйте Redis + Sentinel + Redis Operator.
Отказоустойчивость Sentinel и Cluster имеет свою цену:
Оба варианта меняют протокол взаимодействия с Redis, и клиент должен поддерживать новый вариант
Как минимум 3 экземпляра Redis Sentinel нужно, чтобы достигнуть кворума при выборке master
Сам Redis Sentinel нового мастера не назначит, его надо попросить, что и делает Redis Operator
Взаимодействие PHP-приложения с Redis Sentinel показано на схеме:
Сначала приложение обращается к Redis Sentinel и узнаёт, какой из экземпляров Redis является мастером. Затем приложение обращается к нужному экземпляру Redis.
Допустим, в нашем кластере распределено 3 redis и 3 redis-sentinel, причём redis master и один из sentinel оказались на одной машине #3:
После этого worker #3 вывели на обслуживание, в результате мы теряем redis master и один из redis-sentinel. Пока redis-sentinel не перезапустится на другой машине, а redis operator не попросит всех троих выбрать нового master, redis останется недоступен (по крайней мере на запись).
Чтобы PHP-приложение (или, например, NGINX/Lua) не обращалось к redis-sentinel на каждый запрос, можно ввести ещё одного игрока: redis-proxy (например, ifwe/twemproxy). Этот proxy является stateless, он может быть запущен внутри контейнера PHP-приложения либо как sidecar-контейнер, чтобы минимизировать задержки сети.
Взаимодействие PHP-приложения с Redis Proxy показано на схеме:
Worker, на котором находится redis master, выводится на обслуживание
Запускается новый redis
Посовещавшись, тройка redis sentinel выбирает новый redis мастером
Новый и абсолютно пустой redis в роли мастера просит реплики удалить все данные
Баг, приводящий к такому сценарию, исправили в spotahome/redis-operator, но кто даст гарантию, что это был последний баг?
Избежать проблемы можно путём добавления сетевого диска — например, NFS. Тогда NFS станет ещё одной точкой отказа.
Так что же делать?
Если вы на этапе проектирования, подумайте:
Так ли вам нужен Redis в этом классе/модуле/сервисе? избегайте хранения в Redis важных данные или данных, требующих контроля целостности
Так ли вам нужен Redis в Kubernetes, или подойдёт Redis на отдельной машине?
В целом стоит насторожиться, когда кто-то предлагает засунуть хранилища данных в Kubernetes. Если это предлагает коллега, расскажите ему анекдот про мужика, сено и скафандр.
Вы можете столкнутся с несколькими доводами в пользу применения Redis:
В проекте уже используют Redis
возражение: важно понимать, для чего именно использован Redis и на какие компромиссы при этом согласились
Данные имеют time to life
возражение: это не мешает хранить их в SQL СУБД
Redis быстрее SQL СУБД
возражение: перегруженный redis работает медленее, кроме того, взаимодействие с двумя хранилищами вместо одного добавляет сетевые задержки и точки отказа
Достойная причина использовать Redis — высокие нагрузки и данные, которые не так страшно потерять.
Как улучшить отказоустойчивость
Сложная система порождает новые сценарии катастроф. Что ещё хуже, вы не можете заранее предсказать все риски. Но можно практиковать избыточность, нагрузочное тестирование и тестирование тех сценариев отказа, которые вы можете предсказать.
Избыточность может проявляться по-разному:
В дополнительных сущностях: redis-sentinel, redis-operator, redis-proxy
В распределении redis по разным машинам или даже разным дата-центрам
В дополнительной отказоустойчивости со стороны приложения, а не инфраструктуры
Последний пункт почти не упоминается в статьях об отказоустойчивом Redis, а мы поговорим об этом подробнее.
Делаем кэширование необязательным
Допустим, наше приложение на PHP использует Redis как кэш. В таком случае мы должны:
При записи сохранять данные и в Redis, и в основную БД
При чтении читать сначала из Redis, а при ошибке — читать из БД
Сохранить небольшой timeout для клиента Redis — например, 100 или 300 миллисекунд
Рассмотрим схему классов для хранения данных сессии:
Интерфейс KeyValueCacheInterface объявляет обобщённый API для работы с кэшем, за которым скрыт Redis
Интерфейс SessionStorageInterface объявляет хранилище данных сессии
реализация DatabaseSessionStorage хранит сессии в таблице в БД
реализация KeyValueCacheSessionStorage хранит сессии в кэше
SessionService использует оба варианта хранилища, но работает с ними по-разному
При чтении данных в SessionService сначала пытаемся читать из Redis, в случае ошибки — читаем из БД:
Для обновления данных записываем и Redis, и в БД:
Такое решение имеет свои ограничения:
Возрастёт нагрузка на БД — в сравнении с хранением данных только в Redis
После отказа и восстановления кэша в нём появляются неактуальные данные, записанные в БД в период отказа
Усовершенствование в хранении сессий
На примере всё тех же сессий посмотрим, как можно усовершенствовать механизм отказоустойчивости.
Допустим, у нас есть сессии, которые хранятся в трёх хранилищах: session id хранится в Cookie, а данные сессии хранятся одновременно и в Redis, и в MySQL:
Сессию надо периодически обновлять, чтобы при активном использовании TTL (time to life) не истёк и сессия не закончилась. Чтобы уменьшить частоту обновления сессий, мы можем добавить в данные сессии дату последнего обновления, и обновлять сессию в обработчике запроса только в том случае, если с последнего обновления прошло больше определённого числа секунд (например, 60 секунд).
Кстати, именно так ведут себя современные PHP фреймворки — например, Symfony.
Обновлённое расположение данных будет выглядеть так:
Чтобы решить проблему инвалидации кэша при его недоступности, мы можем добавить в Cookie ещё одно значение: целочисленный generation number данных сессии, который увеличивается на единицу при каждом изменении данных сессии, и предпочитать чтение данных из БД в случае, если generation number в Redis не совпадает с тем, что пришёл из Cookie:
Сессии в Signed Cookies
Идею хранения данных в Cookie можно развить, но для этого надо сделать Cookie надёжным хранилищем, в котором нельзя подменить данные. Этого можно достигнуть с помощью Signed Cookies — например, можно в качестве значения хранить JWT (JSON Web Token). В этом случае:
Секретный ключ для подписи JWT хранится на сервере, и пользователь не может подменить содержимое Cookie, не нарушив целостность подписи JWT.
Секретные данные в Signed Cookie хранить по-прежнему нельзя, т.к. полезная нагрузка в JWT хранится в открытом виде
С таким подходом основные данные сессии можно переместить в Cookie небольшого размера (не более 1-2 КБ), и до истечения JWT вообще не обращаться к Redis и MySQL. Короткое время жизни такой Cookie обеспечит баланс между временем инвалидации данных и снижением нагрузки на сервера.
Состояние сессии, влияющее только на просмотр, можно хранить в открытом виде в Cookie, а можно точно так же поместить в JWT.
После этих изменений схема расположения данных выглядит, как показано ниже. Можно убрать из схемы Redis, поскольку Signed Cookie снизит число обращений к данным сессии на сервере.
Подытожим
Отказоустойчивости в работе с Redis или с любым другим вспомогательным хранилищем можно достигнуть не только за счёт схемы развёртывания и инфраструктуры, но и за счёт пересмотра архитектуры или доработок приложения, обеспечивающих устойчивость к отказам.
Чтобы это сработало, надо:
Учесть разные сценарии отказа Redis, в том числе связанные с превышением таймаутов, превышением лимита памяти или сетевых соединений
Пересмотреть архитектуру и реализацию системы с точки зрения взаимодействия с Redis
Решить, куда вносить доработки: в схему развёртывания, в реализацию взаимодействия с Redis или даже в архитектуру хранения данных
Для большей устойчивости к отказам и нагрузкам потребуется применить все три метода
Кроме того, стоит решить, будет ли использование Redis, memcached или иного быстрого хранилища уместным:
Возможно, требования по нагрузке и отказоустойчивости позволяют не усложнять и хранить всё, включая сессии, в основной БД
Возможно, идея использовать Redis пришла из-за того, что данные временные; в этом случае данные можно так же хранить в БД, не забывая:
Добавить в таблицу и во все связанные SQL-запросы колонку expiration date
Реализовать механизм очистки старых данных фоновыми задачами, запускаемыми через cron или CronJob (в Kubernetes), например, каждую ночь
В микросервисной архитектуре можно выделить работу с сессиями, cookie и токенами в отдельный сервис (который также может взять на себя задачи аутентификации). В монолите можно скрыть работу с Redis за абстракцией, а в реализации этой абстракции Redis рассматривать как вспомогательный кэш, недоступность которого не приводит к отказу.
Установка и настройка кластера Redis в Linux
Кластер Redis часто используется в качестве инструмента для хранения данных их кэширования, брокера сообщений и других задач. Он стал популярным инструментом благодаря возможности масштабирования и высокой скорости работы. В этой статье представлены инструкции по созданию кластера на трех серверах для организации разделения данных (sharding) и высокой доступности за счет репликации. В данной конфигурации в случае отказа узла master, slave-сервер автоматически заменяет его.
Данная статья является переводом и адаптацией англоязычной статьи.
Redis как хранилище, размещаемое в памяти, обеспечивает высокоскоростную обработку таких операций, как подсчет, кэширование, организация очередей и др. Установка кластера значительно увеличивает надежность Redis за счет устранения единой точки отказа.
Установка Redis на каждый сервер
В зависимости от используемой версии Linux, может быть доступна установка Redis через менеджер пакетов. В данном руководстве мы рассмотрим установку текущей стабильной версии из исходного кода.
Сначала установите зависимости необходимые для сборки зависимости:
Скачайте текущую стабильную ветку и извлеките исходный код из архива:
Убедитесь, что тесты сборки проходят успешно:
При успешном завершении, в консоли будет ответ:
Необходимо повторить установку для каждого сервера, который будет входить в кластер.
Настройка узлов Master и Slave
В данной инструкции каждый master будет подключен к одному slave.
Для более удобной работы с несколькими терминалами рекомендуем использовать tmux.
Официальная документация рекомендует использовать 6 узлов — по одному экземпляру Redis на узле, что позволяет обеспечить большую надежность, но возможно использовать три узла со следующей топологией соединений:
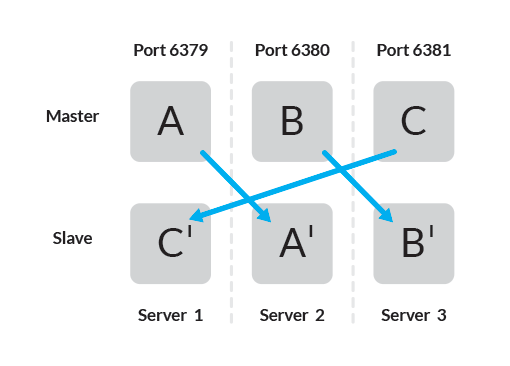
В установке используется три сервера, на каждом из которых запущено по два экземпляра Redis. Убедитесь, что каждый хост независим от других и не выйдет из строя совместно с другим. Далее выполните следующие шаги:
Для каждого узла в проектируемом кластере Redis требуется доступность не только определенного порта, но и порта выше 10000. На сервере 1 оба порта TCP 6379 и 16379 должны быть открыты. Убедитесь, что файрвол настроен корректно.
Повторите процедуру для оставшихся двух серверов, определив порты для всех пар master-slave.
| Server | Master | Slave |
| 1 | 6379 | 6381 |
| 2 | 6380 | 6379 |
| 3 | 6381 | 6380 |
Запуск узлов Master и Slave
Подключитесь по SSH к серверу 1 и запустите оба экземпляра Redis:
Для других двух серверов замените a_master.conf и c_slave.conf соответствующим конфигурационным файлом. Все узлы master будут запущены в режиме кластера.
Создание кластера с использованием встроенного скрипта Ruby
На этом этапе на каждом сервере запущены по два независимых узла master. Дальнейшая установка кластера происходит с помощью скрипта Ruby, который хранится в
Если Ruby еще не установлен, установите его:
Установите пакет Redis для Ruby:
Чтобы запустить скрипт, перейдите в каталог, где находится исходный код Redis и выполните настройку серверов кластера, передав список пар ip:port серверов, которые будут играть роль master:
При успешной установке кластера вернется ответ:
Команды Redis не чувствительны к регистру. Однако для ясности, в данной инструкции мы их пишем заглавными буквами.
На данном этапе в кластере только 3 master-сервера, данные будут распределяться по кластеру, но не реплицироваться. Присоединим к каждому серверу master один сервер slave, чтобы обеспечить репликацию данных.
Добавление узлов Slave
В результате должен вернуться ответ:
Повторите это действие для двух оставшихся узлов:
Распределение данных
Интерфейс командной строки Redis позволяет задать и просмотреть ключи с помощью SET и GET и других команд. Вы можете присоединиться к любому из узлов master и получить свойства кластера Redis.
Используйте команду CLUSTER INFO для просмотра информации о состоянии кластера, например, его размер, хэш слоты, ошибки, если они есть.
Для проверки распределения данных можно установить несколько пар ключ-значение.
Поведение Slave при отказе Master
При использовании данной топологии, при отказе одного из серверов кластер будет полностью работоспособен — узел оставшийся без master-а узел slave станет master-ом.
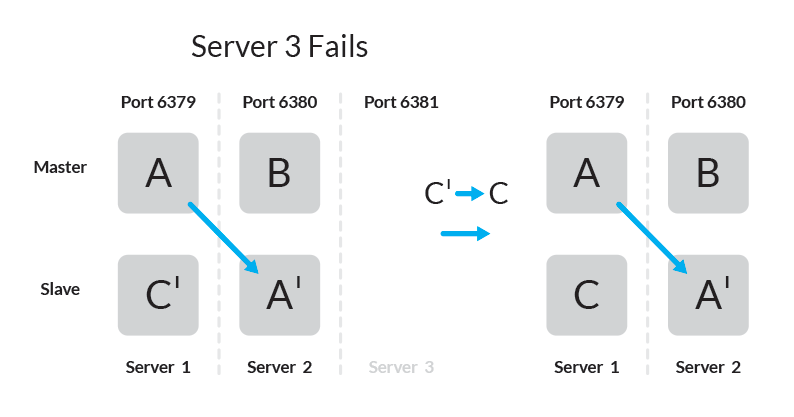
Для проверки добавим пару ключ-значение:
Ключ foo добавлен в master на сервере 3 и скопирован в slave на сервере 1.
В случае, если сервер 3 станет недоступен, slave на сервере 1 станет master и кластер останется доступным.
Для ключа, который был в хэш слоте на сервере 3, пара ключ-значение теперь хранится на сервере 1.
Дополнительная функциональность, например, добавление узлов, создание нескольких узлов slave, или resharding данных не описана в данном руководстве. Подробнее о том, как использовать эти возможности, читайте в официальной документации Redis.
Дополнительные ресурсы
Возможно, вам будут полезны ссылки ниже для получения более подробной информации по теме:
Redis Python based cluster. Часть 1: распределённые системы, теоремы CAP и PACELC и зачем нужен Redis
Рано или поздно сервисы растут, а с большим RPS приходит Highload.
Что делать, когда ресурсов для вертикального масштабирования Redis уже нет, а данных меньше не становится? Как решить эту задачу без downtime и стоит ли её решать с помощью redis-cluster?
На воркшопе Redis Python based cluster Савва Демиденко и Илья Сильченков пробежались по теории алгоритмов консенсуса и попробовали в реальном времени показать, как можно решить проблему с данными, воспользовавшись sharding’ом, который уже входит в redis-cluster.
Воркшоп растянулся на два часа. Внутри этого поста — сокращённая расшифровка самых важных мыслей.
Введение
Немного о тех, кто провёл воркшоп, и почему вообще его решили провести.
 Савва Демиденко
Савва Демиденко
Занимаюсь разработкой в Avito, делаю программу курса «Мидл Python-разработчик» от Яндекс.Практикума. Закончил Бауманку и Технопарк. Разрабатываю на Python и Golang. Люблю решать архитектурные задачи в веб-программировании.
Илья Сильченков
Тимлид в «Сбермаркете» и наставник на курсе «Мидл Python-разработчик». Успел побыть фронтендером и дата-инженером, но остановился на бэкенде. Сейчас пишу на Python и Go.
В рамках нашего курса в «Яндекс.Практикуме» в течение шести месяцев мы делаем онлайн-кинотеатр из множества микросервисов. Сначала пишем маленькую ETL из Elasticsearch и Flask, потом — админку и асинхронное API, авторизацию/аутентификацию и систему уведомлений. В том числе есть маленькая продуктовая задача — пиар в социальных сетях.
Как известно, у Twitter есть смешное ограничение на количество символов. Часто пользователи сокращают ссылки. Один из сервисов нашего курса вставляет ссылку в простенький API, а тот её сокращает и отдаёт обратно.
Для решения этой задачи мы взяли простой стек с прицелом на Python-разработку: FastAPI, асинхронный фреймворк pydantic для валидации и Redis в качестве хранилища данных. Redis суперпростой, однопоточный и отдаёт данные за константное время. Кажется, чтобы сохранить ссылку и достать её, большего и не надо.
К сожалению, с большим RPS приходит highload — то состояние инфраструктуры, которое требует, чтобы ее оптимизировали и масштабировали. Сегодня мы будем решать задачу, когда наше хранилище, а именно Redis, больше не вмещается на одну серверную железку, поэтому нужно придумать, как разъезжаться.
Переезд на другое хранилище — дорогостоящая операция. Почитайте статьи, как Uber переезжал с MySQL на PostgreSQL — там всё ужасно. Речь про события 2013 года: из-за отрицательных результатов через три года в инфраструктуре Uber провели обратный переход. Смена хранилища под нашим сервисом — это последнее, к чему можно прийти.
Перед этим важно понять, как мы расходуем ресурсы, и попробовать оптимизировать хранение данных — перенести какие-то данные в холодное хранилище или удалить. Возможно, мы забывали чистить за собой память, и она засорилась. После всех оптимизаций нужно двигаться в сторону масштабирования.
В итоге хранилище превращается в несколько Redis-машин. До начала работы с практической задачей нужно разобраться с академической стороной вопроса.
Теория
Распределённые системы
Посмотрим, что такое распределённые системы с точки зрения computer science. Это важно понять, потому что от вас ожидают готовое решение, которое будет работать «из коробки». Для этого нужно не наступать на чужие грабли, а теория как раз позволяет их обойти.
Самое простое определение распределённой системы предлагает Лесли Лампорт, создатель алгоритма Паксос. Распределённая система — система, в которой отказ машины, о которой вы даже не подозревали, может превратить ваш компьютер в тыкву. При этом неважно, какая проблема с системой в этом виновата: сеть, электричество или ретроградный Меркурий.
Из этого определения следует, что любой веб-сайт — это распределённая система. В схеме его работы есть устройство клиента и хост-машина, на которую оно ходит. Если хост упадёт, то сайт работать не будет.
Неужели любая система, в которой участвует больше двух железок, распределённая? Почти.
Разберём на примере Redis Cluster. В нём появляются подвиды распределённых систем, для классификации которых потребуется теорема CAP. В ней описывается главное свойство распределённых систем — консистентность.
Википедия превращает консистентность в три отдельных понятия: «…согласованность данных друг с другом, целостность данных, а также внутренняя непротиворечивость».
Рассмотрим пример с обычной реляционной базой данных социальной сети. В ней есть таблица с пользователями и отдельно таблица с друзьями (парами ID). В этом случае целостность означает, что в таблице с парами связей не будет айдишек, которых нет в таблице с пользователями. А если пользователь удалится, то пары с ним либо тоже удалятся, либо не будут учитываться.
Связность означает, что если первый пользователь находится у второго в друзьях, то и второй находится в друзьях у первого. Пары связей согласуются друг с другом. Правило непротиворечивости требует, что если один пользователь удалит другого, то вся связь также будет удалена.
На деле консистентность бывает разной. То, что этом большом дереве с Jepsen.io выделено зелёным — это какой-то вид нормальной консистентности, а всё под ним — технические детали, которые к этому приближают.
Теорема САР
В теореме CAP используется линеаризуемая консистентность — linearazable. Приведём пример, когда это свойство отсутствует.
Допустим, что в распределённой системе есть три ноды: leader и две follower. Судья сказал, что Германия победила в футбольном матче. Insert произошёл на leader, на что тот ответил успехом записи, но раскатал изменения не на всех follower сразу. Алиса зашла и увидела победу Германии, а Боб видит, что матч ещё продолжается — изменение дошло не до всех follower. Если бы в этой системе консистентность была линеаризуемая, то оба участника прочитали бы про победу Германии. Для linearazable-консистентности важно, чтобы лидер ноды отвечал успехом уже после раскатывания на все ноды.
Второе свойство — partition tolerance, или устойчивость к разделению сети или сетевой нестабильности. Например, есть два узла, связанные кабелем. Если его перерубить, то произойдёт то самое разделение сети. Останется два контура со множеством серверов в каждом. Каждой ноде придётся самостоятельно решать, как обеспечивать два другие свойства теоремы CAP. Устойчивость означает, что система знает, как работать в такой ситуации.
Последнее свойство — доступность, или availability. Система ответит быстро, но без гарантии, что быстро и свежими данными. Линейная консистентность не ожидается.
Теорема CAP утверждает принцип тройственной ограниченности: можно получить только два свойства из трёх. Системы делятся на CP, CA и AP. Все системы пытаются покрыть сразу два свойства, а не одно.
Рассмотрим самые простые примеры. В PostgreSQL в синхронной репликации leader и follower связаны жёстко, то есть leader закроет транзакцию только после получения ответа от follower. Если кабель между ними разорвётся, то перестанут работать оба. В теореме CAP такой схеме работы соответствует консистентность и доступность (CA).
В случае асинхронной репликации изначально предусмотрен gap, и может случиться тот самый случай с футбольным матчем. При проблемах с сетью реплики продолжат отвечать в предусмотренное окно. При этом данные будут не самыми свежими. Такая система называется AP: она устойчива к разделению сети и обеспечивает доступность, но не консистентность.
Получается, каждый раз при решении задачи нужно посмотреть в теорему CAP, чтобы выбрать нужные свойства.
Теорема PACELC
PACELC пришла на смену теореме CAP и расширяет её. В ней получается четыре вида систем.
В правом верхнем углу — системы PC/EC, которые всегда выбирают консистентность. Это банки, самолёты и другие надёжные системы.
Кому это не нужно, идут в левый нижний угол — в системы PA/EL. При нарушении сетевой связности (partition) обеспечивается доступность, а в противном случае — скорость ответа (latency). Пример подобной системы — Amazon в «чёрную пятницу». Компания готова возвращать деньги покупателям, одаривать их купонами, дозаказывать товар, но главное — чтобы в этот день клиенты всё заказали. Неважно, будет ли всё в наличии, важно, чтобы можно было оформить заказ.
В левом верхнем углу — системы PA/EC. В случае разбиения сети нужна доступность, в другом случае — консистентность. По данному принципу работает MongoDB, хотя иногда она ближе к системе PC/EC. Если происходит разбиение, возможны нарушения консистентности.
Единственная известная система, которая работает по PC/EL, — поисковик Yahoo. При разбиении нод он выбирает консистентность, потому что ему важно сохранить данные и отвечать единообразно. При отсутствии проблемы он выбирает latency, чтобы быстро давать ответ. Когда всё работает хорошо, поисковики могут игнорировать небольшую неконсистентность уровня секунд и минут.
При чём тут Redis
Redis нельзя рассматривать в теореме CAP. Всё же это однонодовая штука, а теорема CAP — распределённая система хранения данных. Можно рассматривать это как распределённую систему с навешенным поверх сайтом: много нод и кода ходят в один Redis. И получится система CA: если между сайтом и Redis не будет сети, всё упадёт, но при этом каждая нода всё равно будет доступна.
Многие используют Redis в качестве кэширующего слоя. Реже в этой роли выступает Memcached. Но он живёт только в памяти, а комьюнити Redis отлично развивается.
В курсе «Мидл Python-разработчик» мы используем Redis Cluster в асинхронном API. Мы уже разбираем механизмы работы с нодами и как правильно их масштабировать.
Тема непростая, но несколько докладов от Amazon разъясняют, как всё нужно делать, — их вы найдёте в конце поста. Мы далеко не первопроходцы — R&D департамент Amazon это сделал уже в 2007 году.
Итак, в теореме CAP Redis Cluster — это P. Почему только P, без ещё одной буквы?
Обычно так случается, когда кто-то не до конца разобрался с темой и решил разработать собственное решение. Ребята из Jepsen.io провели анализ и сказали, что система устойчива к разделению. При этом она пытается вести себя как кластер. И если половина нод недоступна, работать она уже не может. Это говорит, что Redis Cluster — не система AP.
Остаётся одна P. Если мы используем WAIT, который приделали позже, когда дочитали теорию, Redis Cluster станет CP.
Острова и мосты
Разработка распределённых систем и проверка консистентности — хорошая инженерная задача. Во время анализа нужна какая-то аналогия для ума человека. Задача об обедающих философах — хороший тому пример. Здесь будет аналогия в виде островов и мостов между ними.
Острова живут как одно государство с общим сводом законов. И каждый остров хочет влиять на эти законы. Но не съездом в одном замке с разносом коронавируса, а пересылкой гонцов, как курьеров с едой. И перемещаться между островами они будут по мостам.
На каждом острове мы будем хранить свой свод законов, но с блокировкой изменений ото всех. Важно понимать, что здесь нужен консенсус на чтение и консенсус на запись. Обязательно оговорим, со скольких островов нужно получить информацию, чтобы заявить, что закон работает на 100%. Нужно знать, сколько гонцов необходимо послать на другие острова, чтобы убедиться, что закон записан и теперь мы ему будем следовать.
Чтение — это сбор логов изменения законов к себе. Запись — этот лог изменения законов мы куда-то везём. Именно это — два консенсуса: на чтение и запись.
Если поменять острова на серверы, ничего не пропадёт: как рассуждали, так и останется.
Острова и мосты — это уже традиция. Создатель этого алгоритма Лесли Лэмпорт использует аналогию из алгоритма Паксос. Его конкретные реализации — это ZAB (Apache ZooKeeper) и Raft. Если брать алгоритм, который соответствует Паксосу, то на выходе получится CP.
Спецификации говорят, что Raft простой, но на деле понять его нелегко. На сайте raft.github.io размещена классная настраиваемая браузерная анимация, с которой мы рекомендуем поиграть.
Практика
А теперь представим, что нас есть стажёр, который в первый раз пришёл на работу и впервые видит этот код. Напомним, модуль взят из курса «Мидл Python-разработчик»: на вход получает ссылку, на выходе отдаёт новый хэш, при переходе по хэшу он его разворачивает и даёт редирект. Кажется, просто — погнали!
Заходим в readme. Здесь написано, что это код для вебинара, и описано, как запустить Docker Compose, который облегчает задачу взаимодействия сервисов между собой.

Автор сервиса оставил нам документацию — большое спасибо. Это заслуга FastAPI: документация генерируется автоматически.
У нас есть сервис и файлы конфигурации. Разберём их.

В Dockerfile всё по классике: Python через pip и pipenv, последний уже ставит всё остальное, запускается API на порт 8080.

В файле docker-compose всё просто: Redis и наше приложение на Python. Го его реализовывать.

Мы попали в начало приложения. Здесь какие-то хуки на начало и конец, startup, shutdown. И вот самое интересное: в этом router подвязаны основные ручки.
Чуть не пропустили FastAPI. Кстати, что такое FastAPI?
FastAPI — это классный современный асинхронный фреймворк на Python. Внутри него — pydantic, генерация спецификаций OpenAPI (даже третья версия, а не Swagger!). Просто берёшь и пользуешься: описываешь входные и выходные данные pydantic для валидации, даёшь готовую документацию для других юнитов.
И при этом он асинхронный, что даёт дешёвую работу по сети. Сейчас речь идёт про код, который ждёт других операций: обращения к большому файлу на диске или сетевому ресурсу.
Итак, если у нас не монолитная структура, а микросервисная, то по процессорам и серверам будет значительно дешевле брать асинхронный фреймворк, потому что у него внутри есть event loop, который будет экономить время. Не будем сильно ударяться в event loop, потому что его мы подробно разбираем на курсе — там это основа основ. Мы затрагиваем и корутины, которые идут мостиком к Golang и каналам.

Вернёмся к коду. Нам нужны функции «создать», «проверить» и «редиректнуть». Вот эти три функции.

Разберём, на мой взгляд, самую простую — создание URL. Проговорим логику:

Присутствует околослужебная информация, что мы заинициализировались. А ещё мы отслеживаем коллизии. Вопрос с коллизиями мы решаем добавлением букв. Мы не городим список и не хэшим на ключ, а просто меняем ключ.
Во второй части поста расскажем, зачем нужен Dynamo, и что делать, когда Redis несколько.



