Что такое отражатель маршрутов?
Применимо к: Azure Stack ХЦИ, Versions 21H2 и 20H2; Windows server 2022, Windows server 2019 Windows Server 2016
Отражение маршрутов протокол BGP (BGP) входит в состав шлюза службы удаленного доступа (RAS) и предоставляет альтернативу топологии полной сетки BGP, необходимой для синхронизации маршрутов между маршрутизаторами. Отражатель маршрутов в программно-определяемой сетевой среде — это логическая сущность, которая находится на плоскости управления между шлюзами RAS и сетевым контроллером. Однако он не участвует в маршрутизации в плоскости данных.
Принцип работы отражателя маршрутов
При полной синхронизации с сеткой все маршрутизаторы BGP должны подключаться ко всем другим маршрутизаторам в топологии маршрутизации. Однако при использовании отражателя маршрутов отражатель маршрутизации является единственным маршрутизатором, который соединяется со всеми другими маршрутизаторами, называемыми клиентами отражателя маршрутов BGP, тем самым упрощая синхронизацию маршрутов и уменьшая сетевой трафик. Отражатель маршрутов изучает все маршруты, рассчитывает лучшие маршруты и распространяет лучшие маршруты клиентам BGP.
Вы можете настроить туннели удаленного доступа отдельного клиента для завершения на нескольких виртуальных машинах шлюза RAS. Это обеспечивает повышенную гибкость поставщиков облачных служб в ситуациях, когда одна виртуальная машина шлюза RAS не может удовлетворить все требования к пропускной способности подключений клиентов.
Однако эта возможность предоставляет дополнительную сложность управления маршрутами и эффективную синхронизацию маршрутов между удаленными сайтами клиента и их виртуальными ресурсами в облачном центре обработки данных. Предоставление клиентам подключений к нескольким шлюзам RAS также приводит к дополнительным сложностям в настройке на стороне предприятия, где каждый клиентский узел будет иметь отдельные соседние маршрутизаторы.
Отражатель маршрута BGP в плоскости управления решает эти проблемы и делает развертывание внутренней структуры CSP прозрачным для корпоративных клиентов.
При добавлении нового клиента в центр обработки данных сетевой контроллер автоматически настраивает первый шлюз RAS клиента в качестве отражателя маршрутов.
Каждый клиент имеет соответствующий отражатель маршрутов и находится на одной из виртуальных машин шлюза RAS, связанных с этим клиентом.
Отражатель маршрута клиента выступает в качестве отражателя маршрутов для всех виртуальных машин шлюза RAS, связанных с клиентом. Шлюзы клиента, отличные от отражения маршрутов шлюза RAS, являются клиентами отражательной маршрутизации. Отражатель маршрутов выполняет синхронизацию маршрутов между всеми клиентами отражательных маршрутов, чтобы можно было выполнять фактическую маршрутизацию пути данных.
Отражатель маршрутов не предоставляет службы для шлюза RAS, на котором он настроен.
Отражатель маршрутов обновляет сетевой контроллер с маршрутами предприятия, которые соответствуют корпоративным сайтам клиента. Это позволяет сетевому контроллеру настроить необходимые политики виртуализации сети Hyper-V в виртуальной сети клиента для сквозного доступа к пути к данным.
если Enterprise клиенты используют маршрутизацию BGP в адресном пространстве клиента, отражатель маршрутизации шлюза RAS является единственным внешним соседом BGP (eBGP) для всех сайтов соответствующего клиента. это справедливо независимо от точек завершения туннеля Enterprise клиента. Иными словами, независимо от того, какая виртуальная машина шлюза RAS в центре обработки данных CSP завершает VPN-туннелирование типа «сеть — сеть» для клиентского сайта, узел eBGP для всех сайтов клиента является отражательной стороной маршрута.
Дальнейшие действия
Связанные сведения см. также в следующих статьях:
Принципы работы протокола BGP
Сегодня мы рассмотрим протокол BGP. Не будем долго говорить зачем он и почему он используется как единственный протокол. Довольно много информации есть на этот счет, например тут.
Итак, что такое BGP? BGP — это протокол динамической маршрутизации, являющийся единственным EGP( External Gateway Protocol) протоколом. Данный протокол используется для построения маршрутизации в интернете. Рассмотрим как строится соседство между двумя маршрутизаторами BGP.
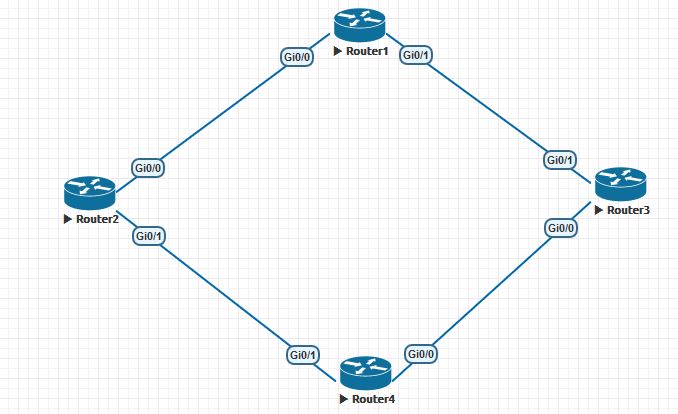
Рассмотрим соседство между Router1 и Router3. Настроим их при помощи следующих команд:
Соседство внутри одной автономной системы — AS 10. После ввода данных на маршрутизаторе, например на Router1, данный маршрутизатор пытается настроить отношения соседства с маршрутизатором Router3. Начальное состояние, когда ничего не происходит называется Idle. Как только будет настроен bgp на Router1, он начнет слушать TCP порт 179 — перейдет в состояние Connect, а когда пытается открыть сессию с Router3, то перейдет в состояние Active.
После того, как сессия установится между Router1 и Router3, то происходит обмен Open сообщениями. Когда данное сообщение отправит Router1, то данное состояние будет называться Open Sent. А когда получит Open сообщение от Router3, то перейдет в состояние Open Confirm. Рассмотрим более подробно сообщение Open:

В данном сообщение передается информация о самом протоколе BGP, который использует маршрутизатор. Обмениваясь Open сообщениями, Router1 и Router3 сообщают друг другу информацию о своих настройках. Передаются следующие параметры:
Для установления соседства необходимо выполнения следующих условий:
Здесь указывают сети, о которых сообщает Router1 и Path attributes, которые являются аналогом метрик. О Path attributes мы поговорим более подробно. Также внутри TCP сессии передаются Keepalive сообщения. Они передаются, по умолчанию, каждые 60 секунд. Это Keepalive Timer. Если в течении Hold Timer-а не будет получено Keepalive сообщение, то это будет означать потерю связи с соседом. По умолчанию, он равен — 180 секундам.
Вроде бы разобрались как маршрутизаторы передают друг другу информацию, теперь попытаемся разобраться с логикой работы протокола BGP.
Чтобы анонсировать какой-нибудь маршрут в таблицу BGP, как и в протоколах IGP, используется команда network, но логика работы отличается. Если в IGP, после указание маршрута в команде network, IGP смотрит — какие интерфейсы принадлежат данной подсети и включает их в свою таблицу, то команда network в BGP смотрит в таблицу маршрутизации и ищет точное совпадение с маршрутом в команде network. При нахождении таких, данные маршруты попадут в таблицу BGP.
Look for a route in the router’s current IP routing table that exactly matches the parameters of the network command; if the IP route exists, put the equivalent NLRI into the local BGP table.
Теперь поднимем BGP на всех оставшихся и посмотрим как происходит выбор маршрута внутри одной AS. После того, как BGP маршрутизатор получит маршруты от соседа, то начинается выбор оптимального маршрута. Здесь надо понять какого вида соседи могут быть — внутренние и внешние. Маршрутизатор по конфигурации понимает является ли сконфигурированный сосед внутренним или внешним. Если в команде:
в качестве параметра remote-as указан AS, который сконфигурирован на самом маршрутизаторе в команде router bgp 10. Маршруты, пришедшие из внутренней AS считаются внутренними, а маршруты из внешней соответственно внешними. И по отношению к каждому работает разная логика получения и отправки. Рассмотрим такую топологию:

На каждом маршрутизаторы настроен loopback интрефейс с ip: x.x.x.x 255.255.255.0 — где x номер маршрутизатора. На Router9 у нас есть loopback интерфейс с адресом — 9.9.9.9 255.255.255.0. Его мы будем анонсировать по BGP и посмотрим как он распространяется. Данный маршрут будет передан на Router8 и Router12. С Router8 данный маршрут попадет на Router6, но на Router5 в таблице маршрутизации его не будет. Также и на Router12 данный маршрут попадет в таблицу, но на Router11 его также не будет. Попытаемся разобраться с этим. Рассмотрим какие данные и параметры передается Router9 своим соседям, сообщая об этом маршруте. Пакет внизу будет отправлен с Router9 на Router8.

Информация о маршруте состоит из аттрибутов пути (Path attributes).
Атрибуты пути разделены на 4 категории:
Атрибут Origin — указывает на то, каким образом был получен маршрут в обновлении. Возможные значения атрибута:
Далее, Next-hop. Атрибут Next-hop
Теперь Router6 передал маршрут Router5 и первому правилу Next-hop не изменил. То есть, Router5 должен добавить 9.9.9.0 [20/0] via 192.168.68.8, но у него нет маршрута до 192.168.68.8 и поэтому данный маршрут добавлен не будет, хотя информация о данном маршруте будет храниться в таблице BGP:
Та же самая ситуация произойдет и между Router11-Router12. Чтоб избежать такой ситуации необходимо настроить, чтоб Router6 или Router12, передавая маршрут своим внутренним соседям, подставляли в качестве Next-hop свой ip адрес. Делается при помощи команды:
После данной команды, Router6 отправит Update сообщение, где для маршрутов в качества Next-hop будет указан ip интерфейса Gi0/0 Router6 — 192.168.56.6, после чего данный маршрут уже попадет в таблицу маршрутизации.
Пойдем дальше и посмотрим появиться ли этот маршрут на Router7 и Router10. В таблице маршрутизации его не окажется и мы могли бы подумать, что проблема как в первом с параметром Next-hop, но если мы посмотрим вывод команды show ip bgp, то увидим, что там маршрут не был получен даже с неправильным Next-hop, что означает, что маршрут даже не передавался. И это нас приведет к существованию еще одного правила:
Маршруты, полученные от внутренних соседей не передаются другим внутренним соседям.
Так как, Router5 получил маршрут от Router6, то другому своему внутреннему соседу он передаваться не будет. Для того, чтобы передача произошла необходимо настроить функцию Route Reflector, либо настроить полносвязные отношения соседства ( Full Mesh), то есть Router5-7 каждый будет соседом с каждым. Мы будем в данном случае использовать Route Reflector. На Router5 необходимо использовать данную команду:
Route-Reflector меняет поведение BGP при передаче маршрута внутреннему соседу. Если внутренний сосед указан как route-reflector-client, то данным клиентам будут анонсироваться внутренние маршруты.
Маршрут не появился на Router7? Не забываем также и про Next-hop. После данных манипуляций маршрут должен и на Router7, но этого не происходит. Это нас подводит к еще одному правилу:
Правило next-hop работает только для External маршрутов. Для внутренних маршрутов замена атрибута next-hop не происходит.
И мы получаем ситуацию, в которой необходимо создать среду при помощи статичной маршрутизации или протоколов IGP сообщить маршрутизаторам о всех маршрутах внутри AS. Пропишем статические маршруты на Router6 и Router7 и после этого получим нужный маршрут в таблице маршрутизаторе. В AS 678 же мы поступим немного иначе — пропишем статические маршруты для 192.168.112.0/24 на Router10 и 192.168.110.0/24 на Router12. Далее, установим отношения соседства между Router10 и Router12. Также настроим на Router12 отправку своего next-hop для Router10:
Итогом будет то, что Router10 будет получать маршрут 9.9.9.0/24, он будет получен и от Router7 и от Router12. Посмотрим какой выбор сделает Router10:
Как мы видим, два маршрута и стрелка ( > ) означает, что выбран маршрут через 192.168.112.12.
Посмотрим как происходит процесс выбора маршрута:
Теперь все маршруты от данного соседа будут иметь такой вес. Посмотрим как изменится выбор маршрута после данной манипуляции:
Но как видим один маршрут через Router6. А где же маршрут через Router7? Может и на Router7 его нет? Смотрим:
Странно, вроде все в порядке. Почему же он не передается на Router5? Все дело в том, что у BGP есть правило:
Маршрутизатор передает только те маршруты, которые использует сам.
Router7 используется маршрут через Router5, поэтому маршрут через Router10 передаваться не будет. Вернемся к Local Preference. Давайте зададим Local Preference на Router7 и посмотрим как отреагирует на это Router5:
Итак, мы создали route-map, в который попадаются все маршруты и сказали Router7, чтоб при получение он менял параметр Local Preference на 250, по умолчанию равен 100. Смотрим, что произошло на Router5:
Посмотрим, что произойдет, если допустим Router6 потеряет маршрут 9.9.9.0/24 через Router9. Отключим интерфейс Gi0/1 Router6, который сразу поймет, что BGP сессия с Router8 оборвана и сосед пропал, а значит и маршрут, полученные от него не действительны. Router6 сразу отправляет Update сообщения, где указывает сеть 9.9.9.0/24 в поле Withdrawn Routes. Как только Router5 получит подобное сообщение, отправит его к Router7. Но так как у Router7 есть маршрут через Router10, то в ответ сразу отправит Update c новым маршрутом. Если детектировать падения соседа по состоянию интерфейса не получается, то придеться ждать срабатывания Hold Timer-а.
Если помните, то мы говорили о том, что часто приходится использовать полносвязную топологию. С большим количеством маршрутизаторов в одной AS это может доставить большие проблемы, чтоб избежать этого необходимо использовать конфедерации. Одна AS разбивается на несколько sub-AS, что позволяет работать им без требования полносвязной топологии.
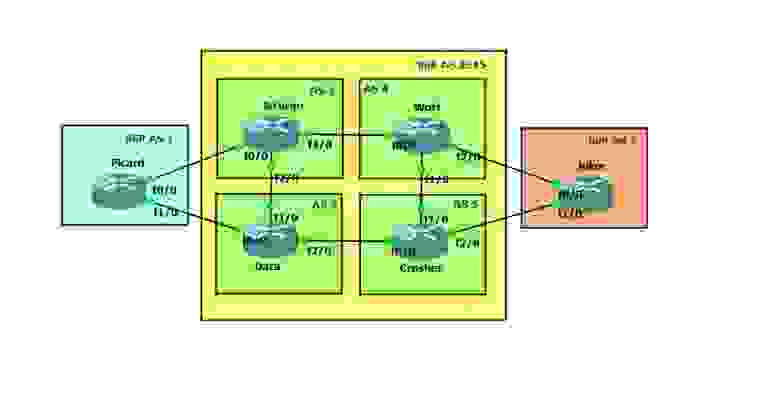
Здесь ссылка на данную лабу, а тут конфигурация для GNS3.
Пришлось бы настраивать Route-Reflector или полносвязые отношения соседства. Разбивая одну AS 2345 на 4 sub-AS ( 2,3,4,5) для каждого маршрутизатора, мы в итоге получаем другую логику работы. Все отлично описано здесь.
BGP: Route Reflector
Доброго времени, господа.
Сейчас мы рассмотрим достаточно интересную тему, которая называется route reflector.
Но сначала давайте постепенно к ней подойдем.
Есть у нас очень много роутеров, а BGP гласит о том, что должна быть Full Mesh.
Представим что у нас 20 роутеров, Full Mesh, это сколько должно быть у нас прописано TCP сессий? Формула простая: n*(n-1)/2, итого: 190 сессий, не мало, не правда ли?
Так же минусом в такой сети является то, что очень много дупликатный роут трафика.
Все это решается двумя механизмами:
Рассмотрим и то и другое, но начнем с рефлекторов.
IBGP Split horizon гласит, что если мы получаем маршрут по IBGP, то мы никому этот маршрут больше не посылаем, а зачем? у нас ведь Full Mesh. Значит нам это нужно изменить 🙂
Есть у нас куча роутеров, нам нужно выбрать один роутер, и сделать его сервером (зеркалом), каждый роутер будет иметь только один линк к этому серверу, такие роутеры называются клиентами. Такой сервер (reflector) и клиенты в совокупности называются кластерами.
Теперь, получая маршрут Route Reflector отправляет своим клиентам этот маршрут, клиент получает и не отправляет никому, ведь у него нет линков больше ни с кем.
Таким образом очнь существенно сокращается количество настройки и конечно же TCP сессий между пирами.
В нашей AS может быть 1 RR (Route reflector), может быть несколько, а может вобще иерархично, давайте посмотрим на правила каждого:
— 1 RR
Если маршрут был получен от своего клиента, то такой маршрут будет перенаправлен не клиентам и своим клиентам.
Если RR получил маршрут от не клиента (от IBGP пира), то такой маршрут будет разослан только своим клиентам.
Если RR получил маршрут от EBGP соседа, то он отсылает этот маршрут всем не клиентам и всем клиентам.
— 2 и более RR
Все RR нужно сконфигурировать с одним Cluster_ID
Все RR с одинаковым Cluseter_ID должны быть Full MEsh
RR клиент должен быть full mesh со всеми RR этого Cluster_ID
— Иерархичные RR
Все роутеры должны быть настроены с одинаковым CLUSTER_ID
RR клиенты должны быть full mesh с RR
RR не должны быть Full-Mesh между собой в случае иерархичности, иерархичность не имеет ограничений по глубине.
Теоретически, используя RR, можно получить петли, BGP предоставляет два механизма защиты от петель, это origitator_id и cluster_list.
Например, у нас есть несколько кластеров, для того чтоб отследить петли, необходим атрибут, который отмечал бы через какие кластера проходит маршрут (похоже на AS-PATH), это отслеживается через cluster-list, RR смотрит и ищит там свой CLUSTER_ID, если он его там находит, то маршрут никому не посылается, просто отбрасывается.
ORIGINATOR_ID это не транзитивный атрибут, этот атрибут представляет собой ROUTER_ID маршрутизатора который создал этот маршрут, если обновление пришло от кого-то и роутер видет тот же ввиде originator_id себя, то такой маршрут отбрасывается.
То есть cluster_list это защита от петель между кластерами, а originator_id внутри кластера. Смысл работы одинаков.
Потенциальные проблемы, которые могут возникнуть при использовании RR:
Если клиент не подключен ко всем RR в кластере, то не будут получены все IBGP маршруты.
Если клиент подключен к нескольким RR разных кластеров, то будут приходить дупликаты.
Если клиент кластера подключен еще к другим клиентам, то будут приходить так же дупликаты.
При правильной настройке RR и правильном планировании таких проблем возникать не должно.
ИТ База знаний
Полезно
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Масштабируемость протокола BGP
В этой статье мы рассмотрим механизмы масштабируемости BGP и связанные с ними концепции.
Онлайн курс по Кибербезопасности
Изучи хакерский майндсет и научись защищать свою инфраструктуру! Самые важные и актуальные знания, которые помогут не только войти в ИБ, но и понять реальное положение дел в индустрии


Предыдущие статьи цикла про BGP:
Механизмы масштабируемости BGP
Истощение доступных автономных системных номеров явилось проблемой точно так же, как было проблемой для интернета истощение IP-адресов. Чтобы решить эту проблему, инженеры обратились к знакомому решению.
Они обозначили диапазон номеров AS только для частного использования. Это позволяет вам экспериментировать с AS конструкцией и политикой, например, в лаборатории и использовать числа, которые гарантированно не конфликтуют с интернет-системами.
Еще одним решением проблемы дефицита, стало расширение адресного пространства имен. Было утверждено пространство, представляющее собой 32-разрядное число.
В течение длительного времени, с точки зрения масштабируемости, одноранговые группы Border Gateway Protocol считались абсолютной необходимостью. Мы настраивали одноранговые группы для уменьшения конфигурационных файлов. Так же мы настраивали одноранговые группы для повышения производительности.
Преимущества производительности были нивелированы с помощью значительно улучшенных механизмов, сейчас. Несмотря на это, многие организации все еще используют одноранговые группы, поскольку они поняты и легки в настройке.
Появились в BGP одноранговые группы для решения нелепой проблемы избыточности в BGP конфигурации. Рассмотрим простой (и очень маленький) пример 1. Даже этот простой пример отображает большое количество избыточной конфигурации.
Пример 1: типичная конфигурация BGP без одноранговых групп
Очевидно, что все команды настройки относятся к конкретному соседу. И многие из ваших соседей будут иметь те же самые характеристики. Имеет смысл сгруппировать их настройки в одноранговую группу. Пример 2 показывает, как можно настроить и использовать одноранговую группу BGP.
Пример 2: одноранговые группы BGP
Имейте в виду, что, если у вас есть определенные настройки для конкретного соседа, вы все равно можете ввести их в конфигурацию, и они будут применяться в дополнение к настройкам одноранговой группы. Почему же так часто использовались одноранговые группы? Они улучшали производительность. Собственно говоря, это и было первоначальной причиной их создания.
Более современный (и более эффективный) подход заключается в использовании шаблонов сеансов для сокращения конфигураций. А с точки зрения повышения производительности теперь у нас есть (начиная с iOS 12 и более поздних версий) динамические группы обновлений. Они обеспечивают повышение производительности без необходимости настраивать что-либо в отношении одноранговых групп или шаблонов.
Когда вы изучаете одноранговую группу, вы понимаете, что все это похоже на шаблон для настроек. И это позволит вам использовать параметры сеанса, а также параметры политики. Что ж, новая и усовершенствованная методология разделяет эти функциональные возможности на шаблоны сессий и шаблоны политики.
Благодаря шаблонам сеансов и шаблонам политик мы настраиваем параметры, необходимые для правильной установки сеанса, и помещаем эти параметры в шаблон сеанса. Те параметры, которые связаны с действиями политик, мы помещаем в шаблон политики.
Одна из замечательных вещей в использовании этих шаблонов сеансов или политик, а также того и другого, заключается в том, что они следуют модели наследования. У вас может быть шаблон сеанса, который выполняет определенные действия с сеансом. Затем вы можете настроить прямое наследование так, чтобы при создании другого наследования оно включало в себя вещи, созданные ранее. Эта модель наследования дает нам большую гибкость, и мы можем создать действительно хорошие масштабируемые проекты для реализаций BGP.
Вы можете использовать шаблоны или одноранговые группы, но это будет взаимоисключающий выбор. Так что определитесь со своим подходом заранее. Вы должны заранее определиться, что использовать: использовать ли устаревший подход одноранговых групп или же использовать подход шаблонов сеанса и политики. После выбора подхода придерживайтесь его, так как, использовать оба подхода одновременно нельзя.
Пример 3: Шаблоны сеансов BGP
Это простой пример настройки соседства с помощью оператора neighbor и использования наследования однорангового сеанса. Затем присваивается имя однорангового сеанса, созданного нами для нашего шаблона сеанса. Это соседство наследует параметры сеанса.
Помните, что, если вы хотите сделать дополнительную настройку соседства, можно просто присвоить соседу IP-адрес, а затем выполнить любые настройки вне шаблона однорангового сеанса, которые вы хотите дать этому соседу. Таким образом, у вас есть та же гибкость, которую мы видели с одноранговыми группами, где вы можете настроить индивидуальные параметры для этого конкретного соседа вне шаблонного подхода этого соседства.
Вы можете подумать, что шаблоны политик будут иметь сходную конструкцию и использование с шаблонами сеансов, и вы будете правы. Помните, что если ваши шаблоны сеансов находятся там, где мы собираемся настроить параметры, которые будут относиться к сеансу BGP, то, конечно, шаблоны политик будут храниться там, где мы храним параметры, которые будут применяться к политике.
Пример 4 показывает настройку и использование шаблона политики BGP.
Пример 4: Шаблоны политики BGP
Да, все эти параметры, которые мы обсуждали при изучении манипуляций с политикой, будут тем, что мы будем делать внутри шаблона политики. Однако одним из ключевых отличий между нашим шаблоном политики и шаблоном сеанса является тот факт, что наследование здесь будет еще более гибким.
Например, мы можем перейти к семи различным шаблонам, от которых мы можем непосредственно наследовать политику. Это дает нам еще более мощные возможности наследования с помощью шаблонов политик по сравнению с шаблонами сеансов.
Опять же, если мы хотим сделать независимые индивидуальные настройки политики для конкретного соседа, мы можем сделать это, добавив соответствующие команды соседства.
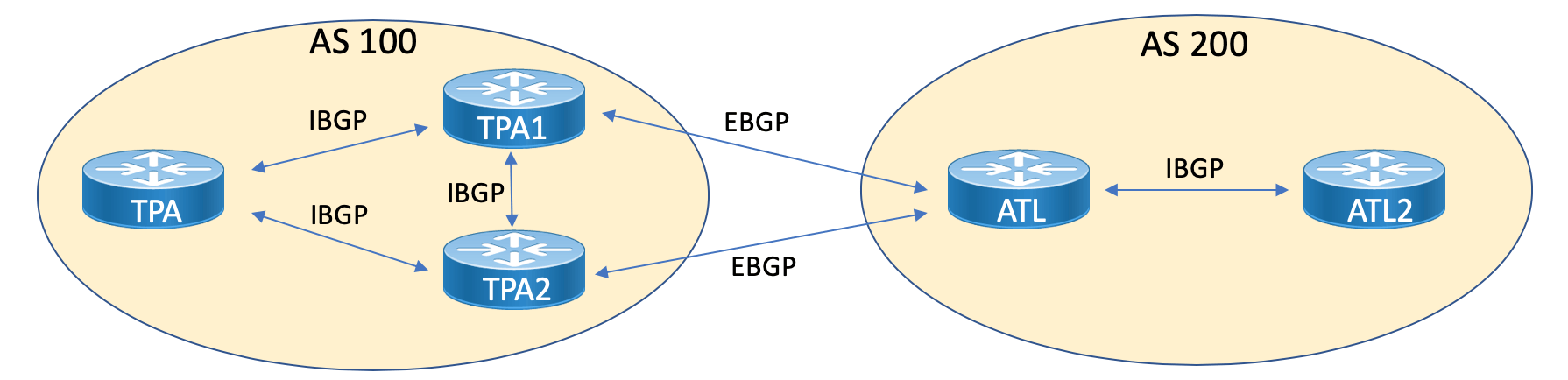
Благодаря предотвращению циклов и правилу разделения горизонта (split-horizon rule) IBGP, среди прочих факторов, нам нужно придумать определенные решения масштабируемости для пирингов IBGP. Одним из таких решений является router reflector.
Рис. 1: Пример топологии router reflector
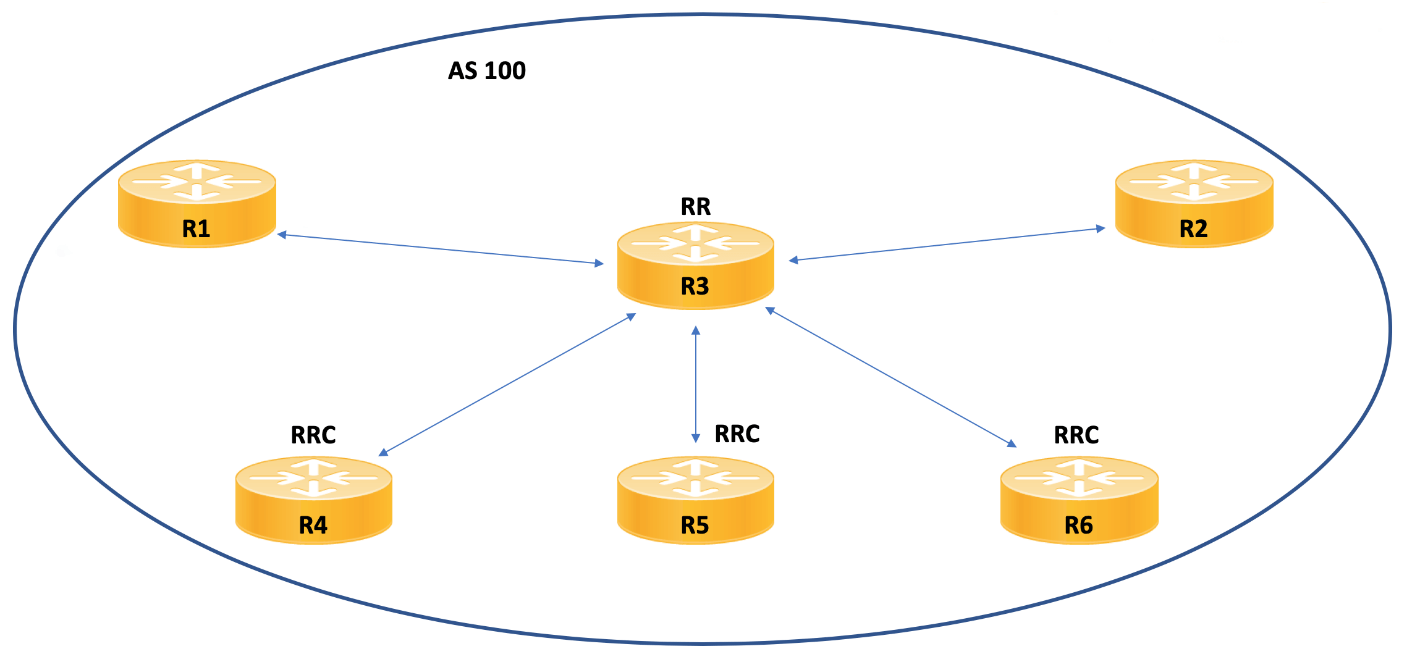
Конфигурация router reflector удивительно проста, поскольку все это обрабатывается на самом router reflector (R3). Клиенты route reflector – это R4, R5 и R6. Они совершенно не знают о конфигурации и настроены для пиринга IBGP с R3 как обычно. Пример 5 показывает пример конфигурации router reflector. Обратите внимание, что это происходит через простую спецификацию клиента router reflector.
Пример 5: BGP ROUTE REFLECTOR
Route reflector автоматически создает значение идентификатора (ID) кластера для кластера, и это устройство и эти клиенты будут частью того, что мы называем кластером route reflector. Cisco рекомендует разрешить автоматическое назначение идентификатора кластера для идентификации клиента. Это 32-разрядный идентификатор, который BGP извлекает из route reflector.
Магия Route reflector заключается в том, как меняются правила IBGP. Например, если обновление поступает от клиента Route reflector (скажем, R4), то устройство R3 «отражает» это обновление своим другим клиентам (R5 и R6), а также своим неклиентам (R1 и R2). Это обновление происходит даже при том, что конфигурация для IBGP значительно короче полной сетки пирингов, которая обычно требуется.
А теперь что будет, если обновление поступит от не клиента Route reflector (R1)? Route reflector отправит это обновление всем своим клиентам Route reflector (R4, R5 и R6). Но тогда R3 будет следовать правилам IBGP, и в этом случае он не будет отправлять обновление через IBGP другому не клиенту Route reflector (R2).
Чтобы решить эту проблему, необходимо будет создать пиринг от R1 к устройству R2 с помощью IBGP. Или, можно добавить R2 в качестве клиента Route reflector R3.
Есть еще один способ, которым мы могли бы решить проблему с масштабируемостью IBGP- это манипулирование поведением EBGP. Мы делаем это с конфедерациями. Вы просто не замечаете, что конфедерации используются так же часто, как Route reflector. И причина состоит в том, что они усложняют нашу топологию, и делают поиск неисправностей более сложным. На рис. 2 показан пример топологии конфедерации.
Рисунок 2: Пример топологии конфедерации
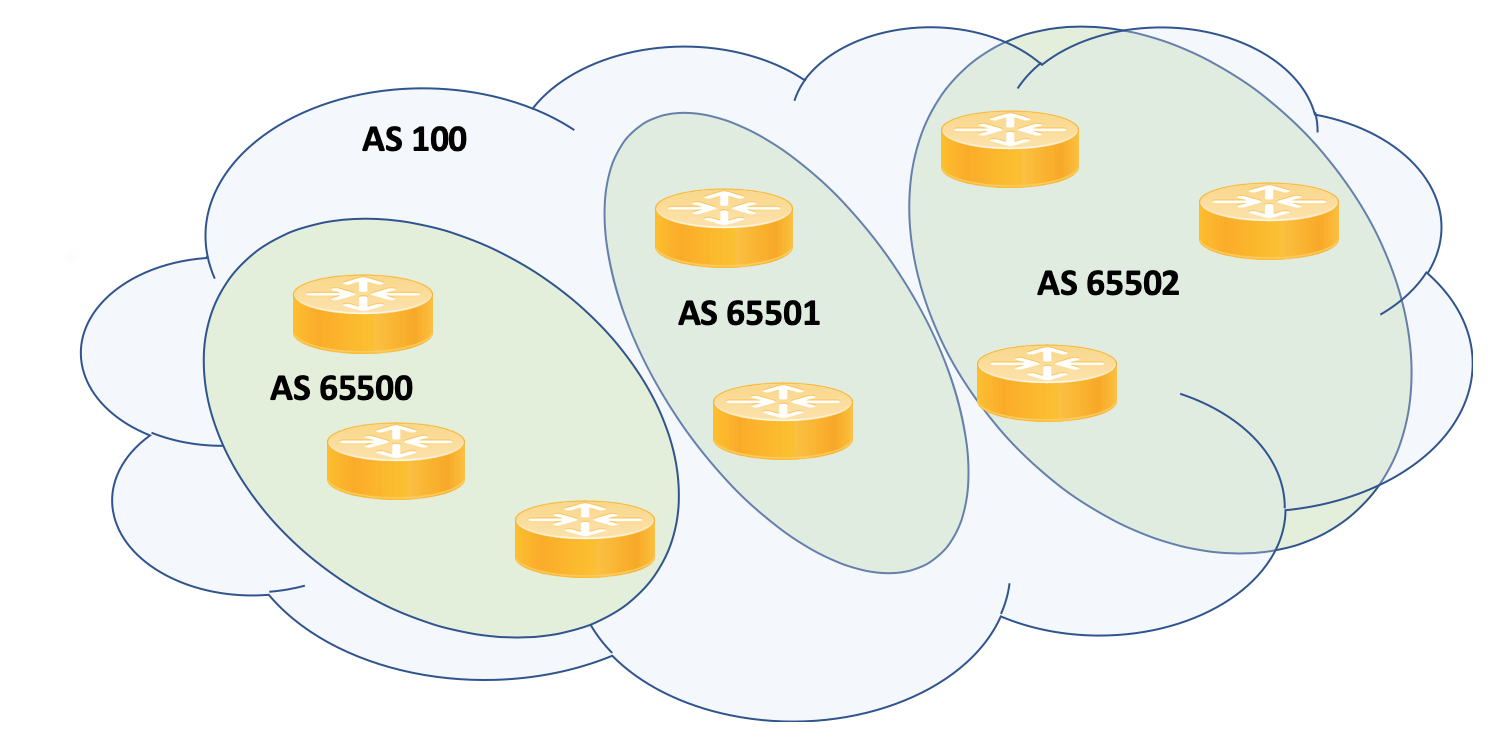
Мы имеем наш AS 100. Для создания конфедерации необходимо создать небольшие субавтономные системы внутри нашей основной автономной системы. Мы их пронумеруем с помощью, номеров автономных систем только для частного использования.
Что мы имеем, когда манипулируем поведением eBGP, что бы имеет конфедерацию EBGP пирингов? Это позволяет нам установить пиринги между соответствующими устройствами, которые хотим использовать в этих автономных системах. Как вы можете догадаться, они не будут следовать тем же правилам, что и наши стандартные пиринги EBGP. Еще один важный момент заключается в том, что все это для внешнего неконфедеративного мира выглядит просто как единый AS 100.
Внутри мы видим реальные AS, и конфедеративные отношения EBGP между ними. Помимо устранения проблемы разделения горизонта IBGP, что же меняется с пирингами конфедерации EBGP? В следующем прыжке поведение должно измениться. Следующий прыжок не меняется тогда, когда мы переходим от одной из этих небольших конфедераций внутри нашей АС к другой конфедерации.
Вновь добавленные атрибуты обеспечивают защиту от цикла из-за конфедерации. Атрибут AS_confed_sequence и AS_confed_set используются в качестве механизмов предотвращения циклов.
Пример 6 показывает пример частичной настройки конфедерации BGP.
Иногда возникает необходимость применения общих политик к большой группе префиксов. Это делается легко, если вы помечаете префиксы специальным значением атрибута, называемым сообществом (community). Обратите внимание, что сами по себе атрибуты сообщества ничего не делают с префиксами, кроме как прикрепляют значение идентификатора. Это 32-разрядные значения (по умолчанию), которые мы можем именовать, чтобы использовать дополнительное значение.
Вы можете настроить значения сообщества таким образом, чтобы они были значимы только для вас или значимы для набора AS. Вы также можете иметь префикс, который содержит несколько значений атрибутов сообщества. Кроме того, можно легко добавлять, изменять или удалять значения сообщества по мере необходимости в вашей топологии BGP.
Атрибуты сообщества могут быть представлены в нескольких форматах. Более старый формат выглядит следующим образом:
Более новый формат:
Есть также хорошо известные общественные значения. Это:
Эти хорошо известные атрибуты сообщества просто идентифицируются по их зарезервированным именам.
Есть также расширенные сообщества, которые также можно использовать. Они предлагают 64-битную версию для идентификации сообществ! Задание параметров осуществляется настройкой TYPE:VALUE. Выглядит оно следующим образом:
Как вы можете догадаться, мы устанавливаем значения сообщества, используя route maps. Пример 7 показывает пример настроек. Обратите внимание, что в этом примере также используется список префиксов. Они часто используются в BGP для гибкой идентификации многих префиксов. Они гораздо более гибки, чем списки доступа для этой цели.
Пример 7: Установка значений сообщества в BGP
Онлайн курс по Кибербезопасности
Изучи хакерский майндсет и научись защищать свою инфраструктуру! Самые важные и актуальные знания, которые помогут не только войти в ИБ, но и понять реальное положение дел в индустрии



