Объясненная и необъясненная дисперсия результирующего показателя.
Цель регрессионного анализа состоит в том, чтобы объяснить поведение переменной Ув зависимости от изменения выбранных факторов X1, Х2,…, Хn. В парном регрессионном анализе мы пытаемся объяснить поведение Упутем определения регрессионной зависимости У от фактораX. Для этой цели используется метод дисперсионного анализа.
Замечание: В математической статистике дисперсионный анализ рассматривается как самостоятельный метод статистического анализа. Мы же будем применять его как вспомогательное средство для изучения качества регрессионной модели.
Согласно основной идеи дисперсионного анализа общую сумму квадратов отклонений переменной у от среднего значения ӯ можно разложить на 2 части: объясненную и необъясненную:
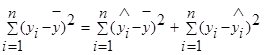
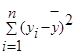 — общая сумма квадратов отклонений (TSS ),
— общая сумма квадратов отклонений (TSS ),
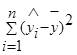 — объясненная или регрессионная сумма квадратов (ESS ),
— объясненная или регрессионная сумма квадратов (ESS ),
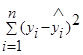 — необъясненная или остаточная сумма квадратов (RSS ).
— необъясненная или остаточная сумма квадратов (RSS ).
Общая сумма квадратов отклонений значения результативного показателя от среднего значения вызвано множеством причин. Условно разделим всю совокупность на 2 группы: влияние изучаемого фактораX и влияние прочих факторов. Если фактор X не влияет наУ, то линия регрессии параллельна оси ОХ (ŷ=ӯ), тогда вся дисперсия результативного показателя обусловлена воздействием прочих факторов. TSS= RSS.
Если же прочие факторы не влияют на результат, тоУ связан с X функционально и остаточная сумма квадратов отклонений отсутствует. TSS=ESS.
Поскольку не все точки корреляционного поля лежат на линии регрессии, то всегда имеется их разброс, обусловленный влиянием как фактора X, так и воздействием прочих причин. Пригодность линии регрессии для прогноза зависит от того какая часть общего отклонения показывается У приходится на объясненную часть. Очевидно, что если ESS>RSS, то уравнение регрессии статистически значимо и фактор X оказывает существенное влияние на результативный показательУ.
Разделив по членено каждое слагаемое равенства (4.1) на соответствующую ей степень свободы, получим средний квадрат отклонений или дисперсию на одну степень свободы.
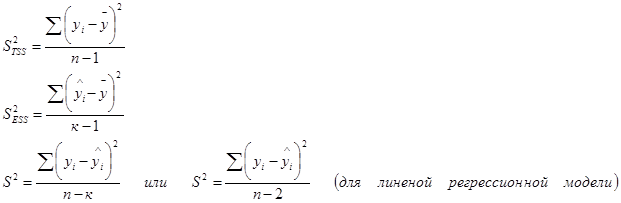
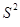 и
и 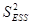 является несмещенными оценками дисперсии результирующего показателя обусловленных соответственно объясненной переменной х и под воздействием неучтенных случайных факторов.
является несмещенными оценками дисперсии результирующего показателя обусловленных соответственно объясненной переменной х и под воздействием неучтенных случайных факторов.
Определение дисперсии на одну степень свободы приводит их к сравнимому виду и это используется в дальнейшем для проверки значимости влияния фактора х на результирующий показатель. (проверка фактора регрессии): для этого определяют:
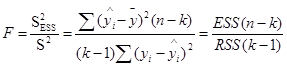 (4.2)
(4.2)
Величина F называется F-критерием (отношение) Фишера.
Проверка статистических гипотез.
Статистической гипотезой H называется предположение относительно параметров или виды распределения случайной величины.
Нулевой (основной) называют выдвинутую гипотезу H0, альтернативной гипотезе H1, которая противоречит основной.
Проверку статистической гипотезы выполняют на основе результатов выборки. Поскольку выборка имеет ограниченный объем, то применяется возможность того, что будет отвергнута правильная нулевая гипотеза называемая уровнем значимости.
a = 5% (0,05) – это означает, что в 5 случаях из 100 верная гипотеза будет отвергнута.
Статистическим критерием (F или t) называется случайная величина, которая служит для проверки нулевой гипотезы. В качестве статистического критерия выбирается такая случайная величина точная или приближенная распределение, которой известно.
Наблюдаемым значением (Fнабл или tнабл) называется значение критерия вычисленного по данным выборки.
Множество значений критерия разбивают на 2 непересекающихся области: критическая и область принятия решений.
Критической областью называется совокупность значений критерии, при которой гипотеза H0 отвергается.
Область принятия решений – это совокупность значений критерия, при которых гипотеза H0 принимается.
Критическими точками называются точки отделяющие критическую область от области принятия решений, и обозначается (Fкр, tкр).
Критические точки определяются по таблицам известного распределения выборочного критерия при заданном уровне значимости a и числе степеней свободы f.
Сравнивая наблюдаемые значения критерия с критическими точками можно принять или отвергнуть нулевую гипотезу.
Пусть нулевая гипотеза состоит в том, что утверждается отсутствие связи между переменными.
Английский статистик Снедекор разработал статистические таблицы значений F – критерия при различных уровнях значимости a и различных степенях свободы f2 и f3.
если Fрас>Fтаб, то H0 отклоняется связь между Х и У существенна;
если Fрас tкр, то H0 отклоняется, т.е. коэффициент данный значим.
Замечание: В эконометрических исследования проверку гипотез осуществляют при 5% и 1% уровне значимости.
Если H0 отклоняется при 1% уровне значимости, то она автоматически отклоняется и при 5% уровне; если H0 принимается при 5% уровне, то она принимается и при 1% уровне; если при 5% уровне гипотезы отклоняются, а при 1% принимается, то результаты проверки гипотез проводятся при обеих уровнях значимости.
В ряде прикладных задач требуется оценить значимость коэффициента корреляции r; для этого проверяется H0 о равенстве нулю теоретического коэффициента корреляции ρ=0. При этом исходят из того, что при отсутствии корреляционной связи статистика: 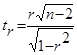 (5.2) имеет t-распределение Стьюдента с n-2 степенями свободы. Коэффициента корреляции r значим на уровне a, если
(5.2) имеет t-распределение Стьюдента с n-2 степенями свободы. Коэффициента корреляции r значим на уровне a, если 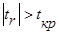 , где tкр – это табличное значение t-критерия при уровне значимости a и числе степеней свободы f=n-2.
, где tкр – это табличное значение t-критерия при уровне значимости a и числе степеней свободы f=n-2.
§ 1.2. Коэффициент корреляции.
Для оценки тесноты корреляционной зависимости используют выборочный коэффициент корреляции r или r(х,у).
где 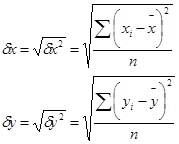
В этом уравнении (2.1) величина 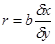 показывает насколько величин dу изменится в среднем у, когда х увеличится dх. Величина r является показателем тесноты линейной связи между х и уи называется выборочным коэффициентом корреляции.
показывает насколько величин dу изменится в среднем у, когда х увеличится dх. Величина r является показателем тесноты линейной связи между х и уи называется выборочным коэффициентом корреляции.
 |
 |
 У
У
 |
| |
 |
 |
 |
 |
Если r>0 (b>0), то корреляционная связь между переменными называются прямой, т.е. при увеличении значения переменной Х увеличивается значение условной средней переменной У.
Дата добавления: 2016-01-16 ; просмотров: 6149 ; ЗАКАЗАТЬ НАПИСАНИЕ РАБОТЫ
Rss что это такое эконометрика
3.4. Проверка адекватности моделей множественной линейной регрессии
3.4.1. Статистические критерии проверки адекватности моделей множественной регрессии
Анализ адекватности модели является важным этапом эконометрического моделирования. Для проверки адекватности моделей множественной регрессии, также как и парной линейной регрессии используют коэффициент детерминации и его модификации, отражающие особенности множественной модели, а также процедуры проверки статистических гипотез и построения доверительных интервалов для оценок параметров и прогнозов зависимой переменной.
3.4.2. Коэффициент детерминации
Важным показателем, характеризующим качество эмпирической регрессионной функции (ее соответствия наблюдаемым данным), является коэффициент детерминации. Полную сумму квадратов отклонений зависимой переменной от ее выборочного среднего в модели множественной регрессии можно представить в виде
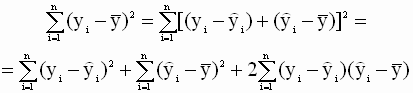 |
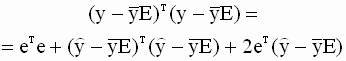 |
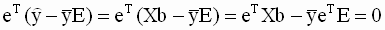 |
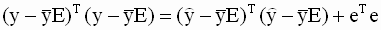 |
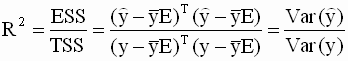 |
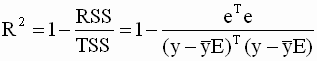 |
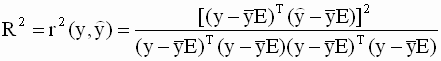 |
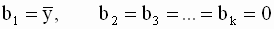 |
и в этом случае, очевидно, 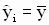 для всех значений i=1,2,…,n. Это означает, что поведение зависимой переменной полностью определяется независимыми случайными ошибками модели, и функция регрессии не объясняет поведение зависимой переменной.
для всех значений i=1,2,…,n. Это означает, что поведение зависимой переменной полностью определяется независимыми случайными ошибками модели, и функция регрессии не объясняет поведение зависимой переменной.
Как и в случае парной линейной регрессии, коэффициент детерминации многомерной (множественной) регрессии следует понимать (интерпретировать) как долю (часть) дисперсии (выборочной) переменной y, объясненную уравнением регрессии. Коэффициент детерминации служит мерой адекватности модели: чем он больше, тем лучше ( при прочих равных условиях ) оценено уравнение регрессии.
Зависимость величины R 2 от количества регрессоров
Общеизвестна следующая зависимость R 2 и количества регрессоров k: если включить в модель дополнительный регрессор, то коэффициент детерминации может при этом только увеличиться. Обозначим 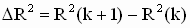 — приращение величины коэффициента детерминации при добавлении дополнительного регрессора, здесь в скобках указано количество регрессоров в модели.
— приращение величины коэффициента детерминации при добавлении дополнительного регрессора, здесь в скобках указано количество регрессоров в модели.
Тогда можно утверждать, что всегда будет 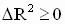 .
.
Действительно, в модели с k+1 регрессором минимизируется функция k+1 переменной
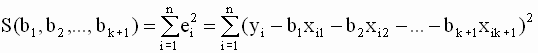 |
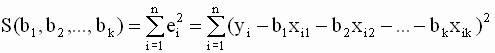 |
3.4.3. Скорректированный коэффициент детерминации
Скорректированный коэффициент детерминации Тейла
Рассмотрим вторую форму представления коэффициента детерминации ( 3.34 ):
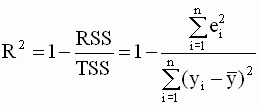 |
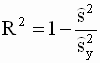 |
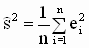 ,
, 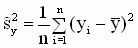 — смещенные оценки дисперсий случайной составляющей модели
— смещенные оценки дисперсий случайной составляющей модели 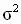 и зависимой переменной
и зависимой переменной 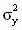 . Если теперь в выражении ( 3.37 ) смещенные оценки дисперсий заменить несмещенными, то получим скорректированный коэффициент детерминации Тейла
. Если теперь в выражении ( 3.37 ) смещенные оценки дисперсий заменить несмещенными, то получим скорректированный коэффициент детерминации Тейла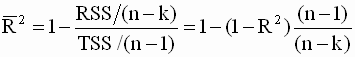 |
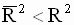 |
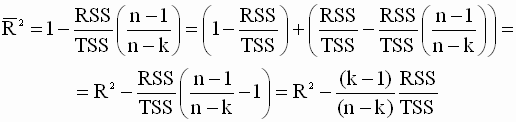 |
откуда и следует неравенство ( 3.39 ).
Ранее было отмечено, что добавление дополнительного регрессора, как правило, увеличивает значение обычного коэффициента детерминации. Этого не происходит, если использовать скорректированный коэффициент детерминации. Его изменение, вызванное добавлением регрессора, может быть как положительным, так и отрицательным и поэтому, ориентируясь на значение скорректированного коэффициента, можно более объективно оценить, целесообразно ли введение дополнительного регрессора при уменьшении степеней свободы (приводит ли это к более адекватной модели). Лучшей признается модель, для которой скорректированный коэффициент 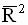 больше.
больше.
Для модели примера 3.1. вычислим коэффициент детерминации и скорректированный коэффициент детерминации Тейла. Используя формулы ( 3.34 ) и ( 3.38 ), соответственно получим:
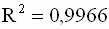 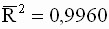 |
Данный результат позволяет сделать заключение о достаточно высоком качестве построенной регрессионной модели.
Вычислим коэффициент детерминации и скорректированный коэффициент детерминации Тейла для регрессии примера 3.2. Их значения равны
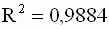 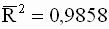 |
соответственно, что также позволяет сделать вывод о достаточно высоком качестве построенной модели.
Сравните результаты примеров 3.3, 3.4 с коэффициентами детерминации парных регрессий в примерах 2.4, 2.5. Сделайте выводы.
3.4.4. Построение доверительных интервалов для параметров регрессии и их линейных комбинаций
Построение доверительных интервалов как для отдельных коэффициентов регрессии так и для прогноза зависимой переменной является важнейшим этапом анализа регрессионной модели. Основные идеи, на которых базируются процедуры построения доверительных интервалов были рассмотрены в разделе ( 2.4.2 ) для случая парной линейной регрессии. Однако в многомерном случае появляются дополнительные задачи, в частности, построения интервалов и проверки гипотез для линейных комбинаций коэффициентов регрессии.
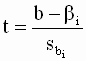 |
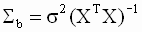 |
В этом выражении неизвестно теоретическое значение дисперсии случайной составляющей модели 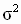 . Оцененная по методу наименьших квадратов ковариационная матрица вектора b получается, если в выражении для теоретической ковариационной матрицы истинное значение дисперсии заменить его несмещенной оценкой. Получим выражение для такой оценки. Вспоминая выражения ( 3.15 ), ( 3.16 ) для оценок параметров и зависимой переменной, запишем
. Оцененная по методу наименьших квадратов ковариационная матрица вектора b получается, если в выражении для теоретической ковариационной матрицы истинное значение дисперсии заменить его несмещенной оценкой. Получим выражение для такой оценки. Вспоминая выражения ( 3.15 ), ( 3.16 ) для оценок параметров и зависимой переменной, запишем
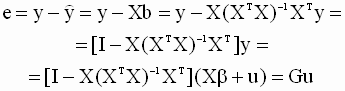 |
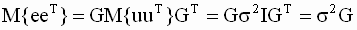 |
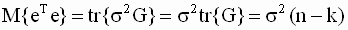 |
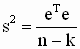 |
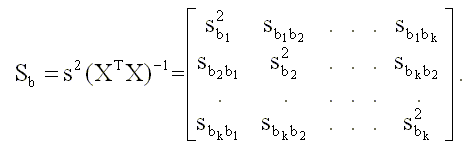 |
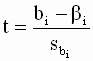 |
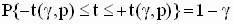 |
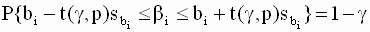 |
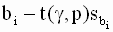 |
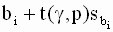 |
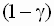 накрывает истинное значение регрессионного коэффициента
накрывает истинное значение регрессионного коэффициента 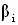 . Уровень значимости выбирают, как и в парной линейной регрессии, либо равным 0,01 (однопроцентный уровень значимости), либо 0,05 (пятипроцентный уровень значимости).
. Уровень значимости выбирают, как и в парной линейной регрессии, либо равным 0,01 (однопроцентный уровень значимости), либо 0,05 (пятипроцентный уровень значимости).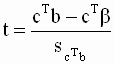 |
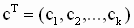 — вектор коэффициентов линейной комбинации с постоянными компонентами,
— вектор коэффициентов линейной комбинации с постоянными компонентами, 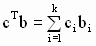 — оцененная линейная комбинация,
— оцененная линейная комбинация, 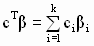 — истинное (теоретическое) значение линейной комбинации,
— истинное (теоретическое) значение линейной комбинации, 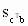 — оценка по методу наименьших квадратов стандартной ошибки линейной комбинации. Получим выражение для этой оценки. Теоретическая дисперсия линейной комбинации
— оценка по методу наименьших квадратов стандартной ошибки линейной комбинации. Получим выражение для этой оценки. Теоретическая дисперсия линейной комбинации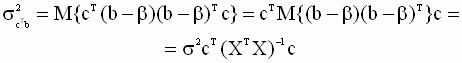 |
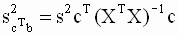 |
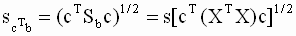 |
Заметим, что в линейной комбинации 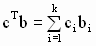 некоторые из коэффициентов
некоторые из коэффициентов 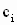 могут быть равны нулю (разумеется, соответствующие коэффициенты в теоретическом значении комбинации также должны быть равны нулю). Границы симметричного доверительного интервала с уровнем значимости
могут быть равны нулю (разумеется, соответствующие коэффициенты в теоретическом значении комбинации также должны быть равны нулю). Границы симметричного доверительного интервала с уровнем значимости 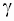 для значения линейной комбинации
для значения линейной комбинации 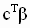 задаются следующим образом:
задаются следующим образом:
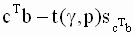 |
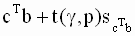 |
Замечание к интерпретации доверительных интервалов.
Процедура проверки гипотез относительно отдельных коэффициентов
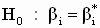 |
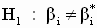 |
Проверка гипотез о линейных комбинациях коэффициентов
Гипотезы о линейных комбинациях коэффициентов множественной регрессии формулируются следующим образом:
 |
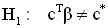 |
Правило проверки этих гипотез: гипотеза 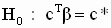 при уровне значимости
при уровне значимости 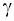 отклоняется, если соответствующий двусторонний симметричный доверительный интервал не накрывает (не включает) значение c * с уровнем доверия
отклоняется, если соответствующий двусторонний симметричный доверительный интервал не накрывает (не включает) значение c * с уровнем доверия 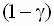 .
.
1. двустороннюю пару гипотез относительно одного, двух или нескольких коэффициентов регрессии;
2. двустороннюю пару гипотез относительно значений одной, двух или нескольких линейных комбинаций коэффициентов регрессии (в отличие от t- теста, который проверяет гипотезу только об одной линейной комбинации);
3. совокупность гипотез относительно коэффициентов и их линейных комбинаций (t- тест подобного рода гипотезы проверять не позволяет).
В общем случае гипотезы для применения F- теста формулируются следующим образом:
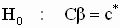 |
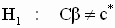 |
Таким образом, с помощью F- теста в общем случае проверяются гипотезы относительно одновременного выполнения (или не выполнения) совокупности m линейных соотношений вида
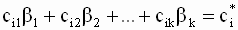 |
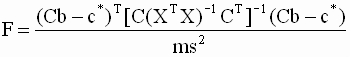 |
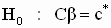 отклоняется, если выполнено неравенство
отклоняется, если выполнено неравенство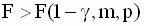 |
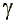 .
.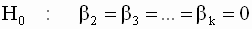 |
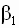 регрессионного уравнения. Очевидно, гипотеза H0 вида ( 3.55 ) является частным случаем общей гипотезы ( 3.51 ), проверяемой с помощью F-теста. Действительно, достаточно матрицу C размерности (k-1) x k в общей формулировке ( 3.51 ) задать в виде
регрессионного уравнения. Очевидно, гипотеза H0 вида ( 3.55 ) является частным случаем общей гипотезы ( 3.51 ), проверяемой с помощью F-теста. Действительно, достаточно матрицу C размерности (k-1) x k в общей формулировке ( 3.51 ) задать в виде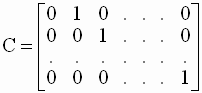 |
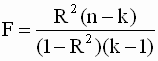 |
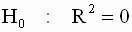 |
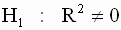 |
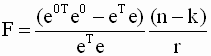
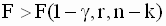 |



